Pracuję nad swoją biblioteką T-Regx, i próbuję ustalić szereg zasad dla poprawnych delimiterów.
foreach (\range(0, 255) as $byte) {
$delimiter = chr($byte);
preg::match($delimiter . 'foo' . $delimiter, 'foo'); // valid or not
}
W PHP, różne delimitery są poprawne dla jednych locale'i, niepoprawne dla innych. Zrobiłem for'a po wszystkich wspieranych locale'ach, i zrobiłem intersekcję, na nich. To jest lista bajtów - przypisane mają true jeśli są poprawne we wszystkich sprawdzanych locale'ach, i false jeśli chociaż w jednym locale'u są niepoprawne. Chciałbym żeby moja biblioteka działała dokładnie tak samo na każdym locale'u, więc muszę znaleźć listę bajtów które są zawsze legalne.
Tutaj jest intersekcja
{"0":false,"1":true,"2":true,"3":true,"4":true,"5":true,"6":true,"7":true,"8":true,"9":false,"10":false,"11":false,"12":false,"13":false,"14":true,"15":true,"16":true,"17":true,"18":true,"19":true,"20":true,"21":true,"22":true,"23":true,"24":true,"25":true,"26":true,"27":true,"28":true,"29":true,"30":true,"31":true,"32":false,"33":true,"34":true,"35":true,"36":true,"37":true,"38":true,"39":true,"40":false,"41":true,"42":true,"43":true,"44":true,"45":true,"46":true,"47":true,"48":false,"49":false,"50":false,"51":false,"52":false,"53":false,"54":false,"55":false,"56":false,"57":false,"58":true,"59":true,"60":false,"61":true,"62":true,"63":true,"64":true,"65":false,"66":false,"67":false,"68":false,"69":false,"70":false,"71":false,"72":false,"73":false,"74":false,"75":false,"76":false,"77":false,"78":false,"79":false,"80":false,"81":false,"82":false,"83":false,"84":false,"85":false,"86":false,"87":false,"88":false,"89":false,"90":false,"91":false,"92":false,"93":true,"94":true,"95":true,"96":true,"97":false,"98":false,"99":false,"100":false,"101":false,"102":false,"103":false,"104":false,"105":false,"106":false,"107":false,"108":false,"109":false,"110":false,"111":false,"112":false,"113":false,"114":false,"115":false,"116":false,"117":false,"118":false,"119":false,"120":false,"121":false,"122":false,"123":false,"124":true,"125":true,"126":true,"127":true,"128":false,"129":false,"130":true,"131":false,"132":true,"133":true,"134":true,"135":true,"136":true,"137":true,"138":false,"139":true,"140":false,"141":false,"142":false,"143":false,"144":false,"145":true,"146":true,"147":true,"148":true,"149":true,"150":true,"151":true,"152":false,"153":true,"154":false,"155":true,"156":false,"157":false,"158":false,"159":false,"160":false,"161":false,"162":false,"163":false,"164":false,"165":false,"166":false,"167":false,"168":false,"169":false,"170":false,"171":false,"172":false,"173":false,"174":false,"175":false,"176":false,"177":false,"178":false,"179":false,"180":false,"181":false,"182":false,"183":false,"184":false,"185":false,"186":false,"187":false,"188":false,"189":false,"190":false,"191":false,"192":false,"193":false,"194":false,"195":false,"196":false,"197":false,"198":false,"199":false,"200":false,"201":false,"202":false,"203":false,"204":false,"205":false,"206":false,"207":false,"208":false,"209":false,"210":false,"211":false,"212":false,"213":false,"214":false,"215":false,"216":false,"217":false,"218":false,"219":false,"220":false,"221":false,"222":false,"223":false,"224":false,"225":false,"226":false,"227":false,"228":false,"229":false,"230":false,"231":false,"232":false,"233":false,"234":false,"235":false,"236":false,"237":false,"238":false,"239":false,"240":false,"241":false,"242":false,"243":false,"244":false,"245":false,"246":false,"247":false,"248":false,"249":false,"250":false,"251":false,"252":false,"253":false,"254":false,"255":false}
Spodziewałem się że ASCII (bajty od 0 do 127) będą się różnić, ale bajty 128 będą zawsze nielegalne. Ale niestety, niektóre są poprawne :o Np 130, 132, 133 :o i inne. Policzyłem je, jest 17 wartości które są poprawnymi delimiterami w zakresie 128-255. Nie mam bladego pojęcia skąd się wzięły.
Próbowałem je porównać do Windows-1250 oraz iso-8859-1, ale nie pasują mi do niczego - tzn code-pointy w tych kodowaniach wydają się zupełnie randomowe. W utf-8 nie ma co szukać, bo single-byte w utf8 to tylko ASCII.
Zacząłem szukać w kodzie źródłowym php, i znalazłem to: https://github.com/php/php-src/blob/master/ext/pcre/php_pcre.c#L656 . To jest if, który sprawdza poprawność delimitera,
if (isalnum((int)*(unsigned char *)&delimiter) || delimiter == '\\') {
Znalazłem tą dokumentację: https://en.cppreference.com/w/cpp/locale/isalnum ale nie potrafię zrozumieć jak różne locale'e wpływają na to czy coś jest isalnum() czy nie. Oraz tak na prawdę, jakiego kodowania spodziewa się ta funkcja.
Tu na przykład jest lista dla polskiego locale'a:
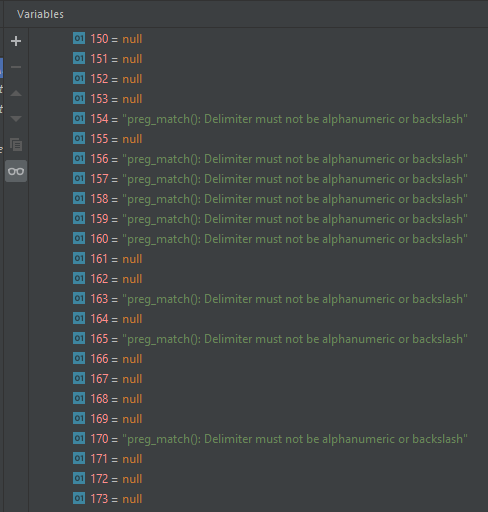
z tego co rozumiem, to jak zrobiłem intersekcję tych 225 locale'i, to spodziewałbym się że prędzej czy później, każdy bajt z zakresu 128-255 będzie nielegalny w którymś, ale te 17 zostały nielegalne. Nie wiem czy pominąłem jakiś locale? Czy po prostu te bajty są zawsze legalne?
Ktoś ma jakiś pomysł?