Jeśli typowa klasa ma u ciebie 450 linijek to prawdopodobnie robisz coś źle, tzn twoja klasa robi zbyt dużo rzeczy naraz.
Przechodząc do twojego problemu (zakładając, że dalej chcesz pisać wielkie klasy).
Ja szczerze mówiąc nie bardzo rozumiem co ma tu IDE do include.
Załóżmy, że mamy taki kod (treść nieważna):
/**
* Copyright (C) 2015 Piotr Tarsa ( http://github.com/tarsa )
*
* This software is provided 'as-is', without any express or implied
* warranty. In no event will the author be held liable for any damages
* arising from the use of this software.
*
* Permission is granted to anyone to use this software for any purpose,
* including commercial applications, and to alter it and redistribute it
* freely, subject to the following restrictions:
*
* 1. The origin of this software must not be misrepresented; you must not
* claim that you wrote the original software. If you use this software
* in a product, an acknowledgment in the product documentation would be
* appreciated but is not required.
* 2. Altered source versions must be plainly marked as such, and must not be
* misrepresented as being the original software.
* 3. This notice may not be removed or altered from any source distribution.
*
*/
#ifndef NUMBERCODEC_HPP
#define NUMBERCODEC_HPP
#include <cstdint>
namespace tarsa {
class NumberCodec {
public:
enum error_t {
OK, NegativeBufferSize, NegativeValue, ValueOverflow,
BufferOverflow, BufferUnderflow
};
protected:
ssize_t bufferPosition;
ssize_t const bufferSize;
error_t error;
public:
NumberCodec(ssize_t const bufferSize) : bufferPosition(0),
bufferSize(bufferSize) {
error = bufferSize < 0 ? NegativeBufferSize : OK;
}
ssize_t getBufferPosition() {
return bufferPosition;
}
error_t getError() {
return error;
}
char const * showError() {
switch (error) {
case OK: return "OK";
case NegativeBufferSize: return "NegativeBufferSize";
case NegativeValue: return "NegativeValue";
case ValueOverflow: return "ValueOverflow";
case BufferOverflow: return "BufferOverflow";
case BufferUnderflow: return "BufferUnderflow";
default: return nullptr;
}
}
};
class NumberEncoder : public NumberCodec {
int8_t * const buffer;
public:
NumberEncoder(int8_t * const buffer, ssize_t const bufferSize) :
buffer(buffer), NumberCodec(bufferSize) {
}
void serializeInt(int32_t const value) {
if (error == OK) {
if (value < 0) {
error = NegativeValue;
} else if (bufferPosition == bufferSize) {
error = BufferOverflow;
} else if (value <= INT8_MAX) {
buffer[bufferPosition++] = value;
} else {
buffer[bufferPosition++] = (value & 127) - 128;
serializeInt(value >> 7);
}
}
}
void serializeLong(int64_t const value) {
if (error == OK) {
if (value < 0) {
error = NegativeValue;
} else if (bufferPosition == bufferSize) {
error = BufferOverflow;
} else if (value <= INT8_MAX) {
buffer[bufferPosition++] = value;
} else {
buffer[bufferPosition++] = (value & 127) - 128;
serializeLong(value >> 7);
}
}
}
};
class NumberDecoder : public NumberCodec {
int8_t const * const buffer;
public:
NumberDecoder(int8_t const * const buffer, ssize_t const bufferSize) :
buffer(buffer), NumberCodec(bufferSize) {
}
private:
int32_t deserializeInt0(int32_t const current, int32_t const shift) {
if (error == OK) {
if (bufferPosition == bufferSize) {
error = BufferUnderflow;
return -1;
} else {
int8_t const input = buffer[bufferPosition++];
if (input == 0) {
return current;
} else {
int32_t const chunk = input & 127;
if ((chunk != 0) && ((shift > 31)
|| (chunk > (INT32_MAX >> shift)))) {
error = ValueOverflow;
return -1;
} else {
int32_t const next = (chunk << shift) + current;
if (input > 0) {
return next;
} else {
return deserializeInt0(next, shift + 7);
}
}
}
}
}
}
int64_t deserializeLong0(int64_t const current, int32_t const shift) {
if (error == OK) {
if (bufferPosition == bufferSize) {
error = BufferUnderflow;
return -1;
} else {
int8_t const input = buffer[bufferPosition++];
if (input == 0) {
return current;
} else {
int64_t const chunk = input & 127;
if ((chunk != 0) && ((shift > 63)
|| (chunk > (INT64_MAX >> shift)))) {
error = ValueOverflow;
return -1;
} else {
int64_t const next = (chunk << shift) + current;
if (input > 0) {
return next;
} else {
return deserializeInt0(next, shift + 7);
}
}
}
}
}
}
public:
int32_t deserializeInt() {
return deserializeInt0(0, 0);
}
int64_t deserializeLong() {
return deserializeLong0(0L, 0);
}
};
}
#endif /* NUMBERCODEC_HPP */
NetBeans bardzo ładnie mi go koloruje:

Jeśli z jakiegoś powodu wytnę sobie ciało funkcji i przeniosę do innego pliku to tracę całe wsparcie od IDE:
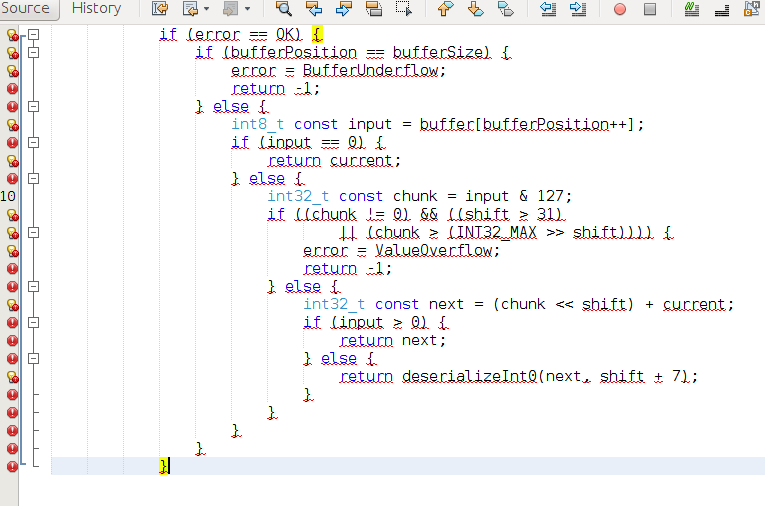
Oprócz kolorowania tracę chociażby podpowiadanie, nawigację i sprawdzanie błędów składniowych w trakcie pisania.
Teraz może pokażę jak się pracuje w świecie Javowym na przykładzie IntelliJ IDEA.
Po pierwsze, jeśli lubimy bardzo widzieć listę metod to jest opcja "Show Members" i prezentuje się to tak:
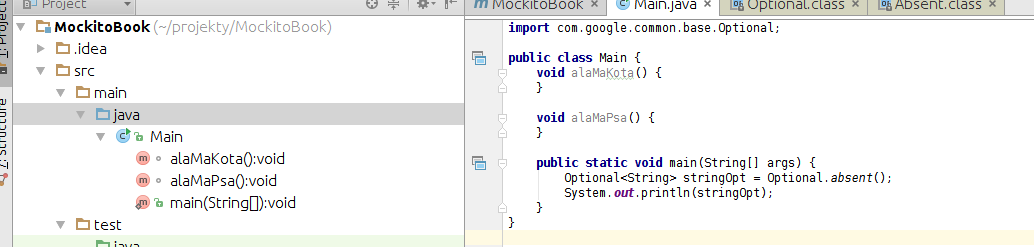
Jak widać, jest lista wszystkich metod i pól z klasy (tutaj pól nie ma, ale jak dołożę to się pojawią w drzewku z lewej). Po dwukliku przechodzimy do metody.
Z czegoś takiego zwykle się jednak nie korzysta i ta opcja jest domyślnie wyłączona (nie powinno być problemu z jej włączeniem, to dosłownie dwa kliknięcia).
Normalni Javowcy korzystają z nawigacji będącej dzisiaj podstawą IDE. Zamiast samemu się produkować odsyłam do gotowej próbki możliwości: https://medium.com/@andrey_cheptsov/top-20-navigation-features-in-intellij-idea-ed8c17075880
Jako wieloletni użytkownik IntelliJ zapewniam, że nawigacja w nim jest superszybka.


