Na wstępie zaznaczam- nie ma złotych środków i jedynie proponuję jedno z możliwych rozwiązań.
Jak zawsze, należy zachować zdrowy rozsądek i wybrać optymalne rozwiązanie. Zwróć uwagę że napisałeś:
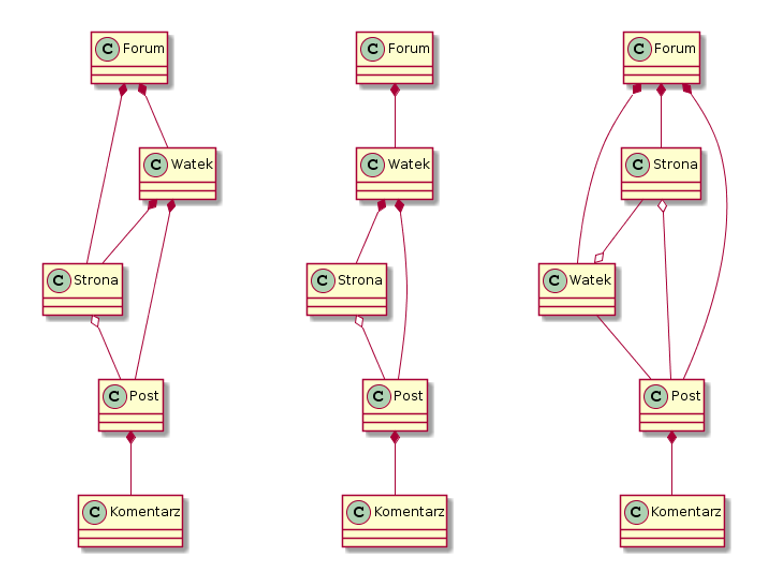
Wydaje się logiczne, że post nie ma globalnej tożsamości więc będzie wchodził w skład wątku.
Agregat to przede wszystkim granica transakcyjności (transactional boundary, nie wiem czy tak to się tłumaczy na język polski). Należy się kierować przede wszystkim tą zasadą kiedy myśli się o modelowaniu agregatów. Również nie ma nic złego w bardzo małych, jedno-encyjnych agregatach jeśli ma to sens i spełnia warunek pierwszej zasady. Piszę to dla tego że należało by odpowiedzieć sobie na pewne pytania:
- Czy zmiana treści postu wymaga zaangażowania wątku?
- Czy zmiana treści wątku (np. tytuł) wymaga zaangażowania postów?
- Czy posty mogą zostać usunięte oddzielnie od usuwanego właśnie wątku?
Dodatkowo dochodzi wymieniony przez Ciebie problem potencjalnie dużej ilości postów w wątku, oraz samych postów mających dodatkowe atrybuty (nie mylić z atrybutami w kodzie) takie jak polubienia. Wracamy więc do pytań:
- Czy załadowanie wątku oznacza konieczność załadowania wszystkich postów wraz z ich "wewnętrznymi" atrybutami?
- Czy polubienie postu jest elementem "transakcji" całego wątku?
Moim zdaniem na podstawie tych pytań i informacji które podałeś wynika że Post jest świetnym kandydatem aby być agregatem samym w sobie, z encją Post jako root oraz np. Polubienie jako value object zawierający ID Posta i użytkownika który to polubił.
@Charles_Ray wspomniał że Wątek może być tylko view modelem Poszedł w dobrym kierunku, problem tylko że- jak mniemam- wątek również może być edytowany (tytuł, treść?) oraz zamykany i/lub usuwany. W tej sytuacji Wątek to również kandydat na agregat. Natomiast wspomnienie modelu widoku jest jak najbardziej trafne. Należy pamiętać że agregaty należą do warstwy modelu domeny, i same w sobie nie powinny mieć nic wspólnego z obsługą widoku. Co za tym idzie zainteresuj się CQRS i Materialized View. Wydaje mi się że Twój scenariusz wymaga takiego zastosowania- na podstawie tego co zachodzi w domenie będziesz mógł budować widok obsługujący konkretne wymagania- w Twoim przypadku zwracający wątek (a konkretnie informacje o wątku) oraz podzbiór postów filtrowany na podstawie strony którą aktualnie przegląda użytkownik.