Test jaki zrobiłem z moim procesorem intel core i3 6157 który ma dwa rdzenie i cztery watki (2/4), wykazał, że cztery wątki procesor wykonuje w czasie cztery razy szybszym, czyli tak samo szybko jakby miał cztery rdzenie. Ciekawe jest to od czego zależy, że w niektórych sytuacjach procesor 2/4 wykonuje cztery wątki dużo wolniej niż procesor 4/4. Czy da się określić rodzaj obliczeń dla 2/4 które będą wolno wykonywane w porównaniu z 4/4? Mam różne obliczenia matematyczne i dobrze byłoby wiedzieć czy rozkładać je na wątki.
0
1
Obliczenia zazwyczaj są takie same tylko Sanę inne wiec kod na wątkach jest ten sam dlatego udaje się wykonać go na raz. Spróbuj natomiast wykonać zupełnie różne zadania - wtedy nie uda się tego zrównoleglić i będą pracowały 2 wątki i będzie przełączany kontekst miedzy 4 zadania.
0
Gdzieś widziałem kiedyś fajne porównanie:
2 wątki to jak jedna kasa, ale dwie kolejki. Kasjerka na zmianę obsługuje ludzi z jednej oraz drugiej strony. Jest jakiś zysk w wydajności, ale nie jest on tak duży, jakbyś miał dwie kasy z dwiema kasjerkami ;)
0
cerrato napisał(a):
Gdzieś widziałem kiedyś fajne porównanie:
2 wątki to jak jedna kasa, ale dwie kolejki. Kasjerka na zmianę obsługuje ludzi z jednej oraz drugiej strony. Jest jakiś zysk w wydajności, ale nie jest on tak duży, jakbyś miał dwie kasy z dwiema kasjerkami ;)
To wszystko jest wiadome, ale ja potrzebuję konkretów, jaki rodzaj obliczeń spowolni wykonanie na 2/4 w porównaniu z 4/4. Dałem te same rzeczy do obliczenia dla innego zakresu liczb dla każdego wątku podzielone na cztery wątki na procesorze 2/4. Program wykonał się dokładnie cztery razy szybciej. Dywagacje przypuszczenia nic mi nie dadzą.
0
No nie do końca. Rdzeń to toster. Jak masz dwie kolejki ludzi i każdy chce tosta to ładujesz po dwie kromki do testera i idzie 2razy szybciej. Jak jedna kolejka chce tosta a druga jajecznicę - musisz przełączać kontekst miedzy patelnia a tosterem i nie możesz obsługiwać 2 kolejek na raz jak w przypadku tostów jedynie.
0
Jakie to obliczenia? Jeśli takie same to nie zauważysz różnicy. Musza być różne i musisz zapewnić żeby procesor nie czekał na dane bo może wąskim gardłem jest pamięć i wcale nie badasz prędkości procesora.
0
Zwykle to kwestia cache, jeżeli wątki czytają te same dane to dla 2/4 będzie to szybsze, ponieważ masz jeden cpu i wspólny cache dla dwóch rdzeni, mniej jest też synchronizacji przy zapisach.
1
Wszelakie porównania do tostera czy kasjerki są bez sensu. SMT działa dlatego, że w bardzo wielu przypadkach wątek nie obciąża wszystkich struktur rdzenia w 100% bądź jeden wątek wykorzystuje jedne struktury, a drugi inne. Ponadto pewne struktury mogą być statycznie podzielone na wątki i wtedy ich wykorzystanie nie wpływa na wydajność SMT. Przykład (AMD Zen 1):
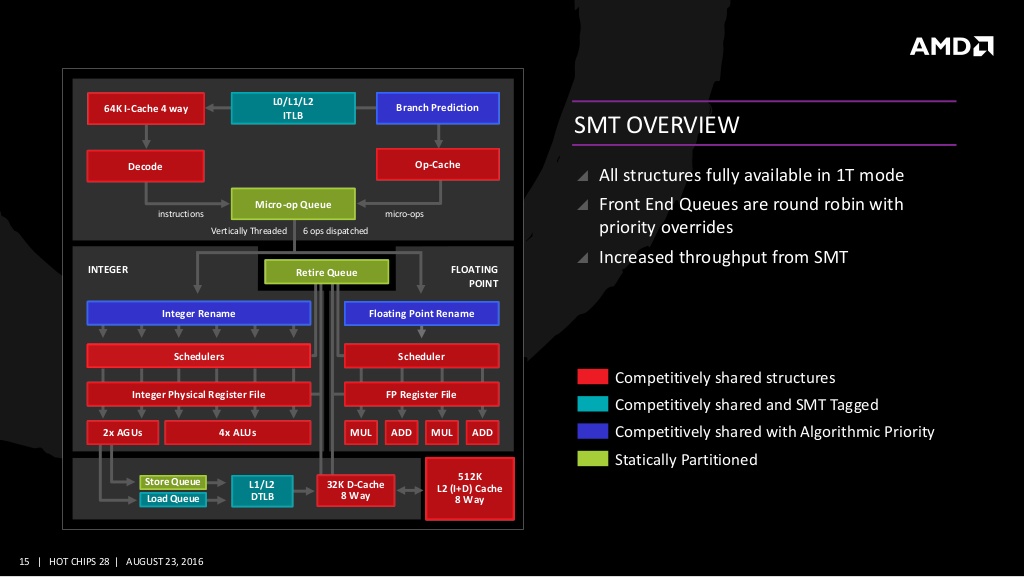
Jeśli np jeden wątek ciśnie jednostki typu integer w 100%, a drugi wątek ciśnie zamiast tego jednostki typu floating point w 100% to prawdopodobnie wykonywanie ich jednocześnie na tym samym rdzeniu będzie szybkie. Natomiast jeśli oba wątki wysycają te same struktury w rdzeniu to zysk z SMT będzie żaden. Jak sprawdzić które struktury są wysycone? W ogólnym przypadku jest to na tyle trudne, że nie warto tego precyzyjnie mierzyć. Lepiej skupić się ogólnie na zrównolegleniu algorytmu, a SMT traktować jako dodatek zwiększający wydajność. SMT to ruchomy cel - nowa generacja procesorów może mieć np 2x więcej jednostek integer, a tyle samo jednostek floating point. To by oznaczało, że SMT będzie działać lepiej dla kodu typu integer, a tak samo dla kodu typu floating point. Tego typu współczynników mających wpływ na skalowanie SMT jest multum i ciągle się zmieniają, więc nie warto tego specjalnie śledzić. Ze względu na ciągłą zmienność, nie da się napisać kodu optymalnego pod wszystkimi mikroarchitekturami CPU. W kompilatorach są nawet oddzielne przełączniki do sterowania zestawem używanych instrukcji i sposobem ich układania w kodzie natywnym. -march w GCC wpływa na zestaw używanych instrukcji, a -mtune wpływa na sposób ich układania. Pewne ułożenie instrukcji będzie lepsze np dla Core 7 generacji, inne dla Core 3 generacji, inne dla Zena 1, inne dla Pentiuma 1, itd Z SMT jest jeszcze taka sprawa, że wcale nie musi być tak, że rdzeń obsługuje maksymalnie dwa wątki naraz. Są procesory SMT4 czy SMT8. Intel czy AMD też mogą na takie SMT4 przejść, bo rdzenie są coraz bardziej rozrośnięte i w coraz mniejszym stopniu wykorzystywane przez typowy pojedynczy wątek czy nawet dwa wątki.
0
Najlepsze chyba będzie porównanie rdzeni do stanowisk roboczych, a wątków do pracowników. Jak korzystają z różnych narzędzi, to mogą wykonywać jednocześnie 2 prace (2 wątki na fizycznym rdzeniu), a jak potrzebują tych samych to wtedy jeden musi czekać (jeden wątek na rdzeń).
0
Jakieś konkrety techniczne tych obliczeń? Język? Kod? Napisz to samo w 3-4 różniących się od siebie językach, i daj wtedy wyniki.
0
To nie ma żadnego sposobu żeby teoretycznie obliczyć jakie będzie przyspieszenie 4/4 w porównaniu z 2/4? Tylko zostają testy na próbnych danych? I nadzieja że jak zbiór danych rozszerzymy to proporcje czasu wykonania pozostaną te same i dzięki temu próba wykaże czy warto puścić program na całych danych. Gorzej będzie wtedy, jeśli się okaże że trzeba dużo kodu wpisać żeby ten test zrobić. W sumie i tak zauważyłem że spory zysk się uzyskuje, jeśli nie 100% to 70%, czyli wątki równoległe 2/4 nie zadziałają tak szybko jak 4/4 tylko 10/7 tego czasu. Tak jak kolega napisał, instrukcje assemblera są rozkładane na mikrorozkazy sprzętowe procesora i z jednego wątku brane są inne mikroinstrukcje niż z drugiego, czyli inna część procesora może je wykonać równolegle. Wymagało to sporych prac nad architekturą procesora i jakichś nowych poleceń assemblera który daje taka komendę do podziału zadań w nowych systemach operacyjnych.
0
Można policzyć, ale musisz wiedzieć jak Twój program się wykona na procesorze więc musisz dobrze znać jak dany język implementuje np. kolekcje lub jakie optymalizacje wykonuje maszyna wirtualna. bez kodu oi tego co chcesz robić to jest wróżenie.
0
Wymagało to sporych prac nad architekturą procesora i jakichś nowych poleceń assemblera który daje taka komendę do podziału zadań w nowych systemach operacyjnych.
SMT nie wymaga korzystania specjalnych instrukcji przez program użytkownika. Możesz wziąć wielowątkowy program sprzed wprowadzenia SMT w x86 (czyli sprzed czasów Pentium 4) i będzie on wykorzystywał SMT tak samo jak osobne rdzenie.
System operacyjny oczywiście musi mieć wsparcie dla SMT, tak samo jak musi mieć wsparcie dla wielordzeniowości. x86 startuje w trybie jednowątkowym i OS musi sobie konkretne rzeczy poustawiać.