Cześć, mam zadanie. Dość proste jednak wymagania czasowe są dość duże bo wymaga wykonania poniżej 1s
Napisz program, który:
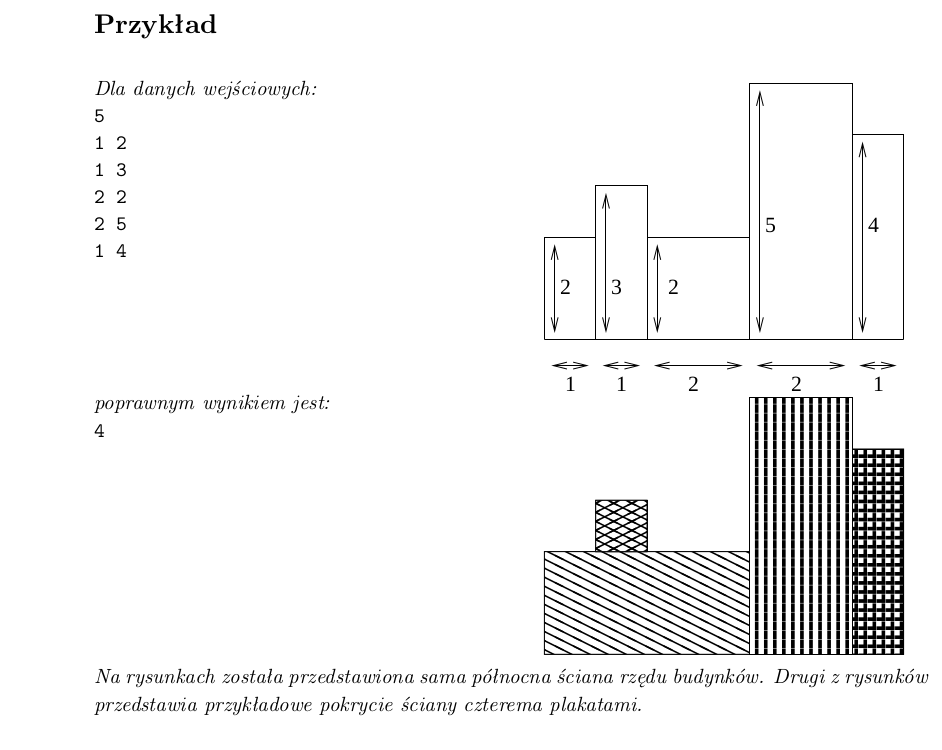
• wczyta ze standardowego wejścia opisy budynków,
• wyznaczy minimalną liczbę plakatów potrzebnych do całkowitego pokrycia ich północnych
ścian,
• wypisze wynik na standardowe wyjście.
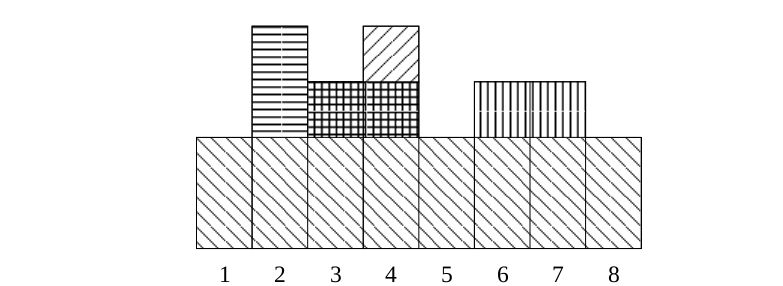
Plakaty się dotykają, mogą powtarzać.
I napisałem coś takiego:
Najpierw skanuje ilość budynków a potem ich wymiary x i h
#include <iostream>
#include <stdio.h>
#define MAXINT 2147483647
using namespace std;
int main()
{
int size;
int *psize = &size;
scanf("%d",psize);
int tablica[*psize+1];
tablica[*psize] = -1;
int *pointer = &tablica[0];
int *pointerNaNajmniesza;
int najmniejsza = MAXINT;
pointerNaNajmniesza = &najmniejsza;
int toLOST;
for(int i = 0; i <*psize; i++)
{
scanf("%d %d",&toLOST,pointer);
if(*pointerNaNajmniesza > *pointer)
*pointerNaNajmniesza = *pointer;
if(size-i==1)
break;
pointer++;
}
for(int i = 0; i <*psize; i++)
{
*pointer = *pointer-*pointerNaNajmniesza;
if(*pointer == 0)
*pointer = -1;
if(size-i==1)
break;
pointer--;
}
toLOST = 1; // pierwszy plakat najniższy poziomy
// teraz algorytm po powstałych grupach
int stoper = 0;
int *pointerStoper = &stoper;
*pointerNaNajmniesza = MAXINT;
for(int i = 0; i < *psize; i++)
{
while(true)
{
*pointerNaNajmniesza = MAXINT;
*pointerStoper = 0;
if(*pointer > 0)
{
while(true)
{
if(*pointer == -1)
break;
if(*pointerNaNajmniesza > *pointer)
*pointerNaNajmniesza = *pointer;
*pointerStoper+=1;
pointer++;
}
for(int i = 0; i < *pointerStoper; i++)
{
pointer--;
*pointer = *pointer-*pointerNaNajmniesza;
if(*pointer == 0){
*pointer = -1;
}
}
toLOST++;
}
else
{
pointer++;
break;
}
}
}
printf("%d",toLOST);
return 0;
}
chodzi o to że w momencie wczytywania wykrywam najmniejszy.
Przesuwam się po tablicy pojedynczo wracając na początek i usuwam o najmniejszy i tam gdzie 0 ustawiam jako wielkość -1 - taki znacznik.
Potem już pętla for a w niej inne, i chodzę po tablicy do momentu znalezienia -1 co jest wyznacznikiem powstałej grupy. Stoper mi mówi ile przeszedłem do -1 czyli jak ta grupa jest duża i od razu skanuje najmniejszy. Wracając obniżam poziom o najmniejszy i inkrementuje ilość plakatów.
I przesuwam się dalej po wskaźnikach. Jeżeli wielkość jest większa od 0 to dalej ten sam algorytm.
I tutaj moje pytanie, czy sam ten proces jest czasochłonny sam z siebie czy może to pierwszy powrót na początek wraz z kasowaniem dużo zajmuje czasu?
przykładowe "in'y" mają po kilkaset tysięcy przykładowych budynków.
Dla nich proces trwa kilkanaście s, a wymóg to 1s max
Z góry dziękuję za jakąś radę jak to uefektywnić