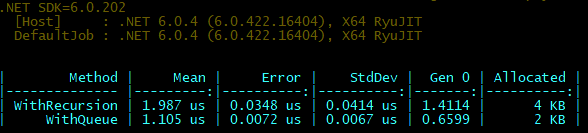
Nie jestem dobry w algorytmice więc nie wiem jak zatytułować ten wątek. Mam taką zagwozdkę:
class Item
{
public string Id { get; init; }
public IList<Item> Items { get; init; } = new List<Item>();
}
class Root
{
public IList<Item> Items { get; init; } = new List<Item>();
}
Więc obiekt typu Root ma teoretycznie nieograniczoną kolekcję obiektów typu Item, każda instancja Item ma teoretycznie nieograniczoną kolekcję instacji Item, gdzie każda instancja ma... Wiecie o co chodzi. To co ja muszę zrobić to dla każdego itemu wziąć jego ID, i upewnić się że żaden inny item zaczynając od roota nie ma takiego samego ID. Ktoś ma pomysł jak to zrobić żeby było w miarę zgrabnie i efektywnie? Jedyne co mi przychodzi do głowy to podejść do tego rekurencyjnie, ale nie wydaje mi się to efektywne zważywszy że dla każdego elementu trzeba by się zagnieżdżać w poszukiwaniu danego ID, i tak dalej dla każdego kolejnego elementu.