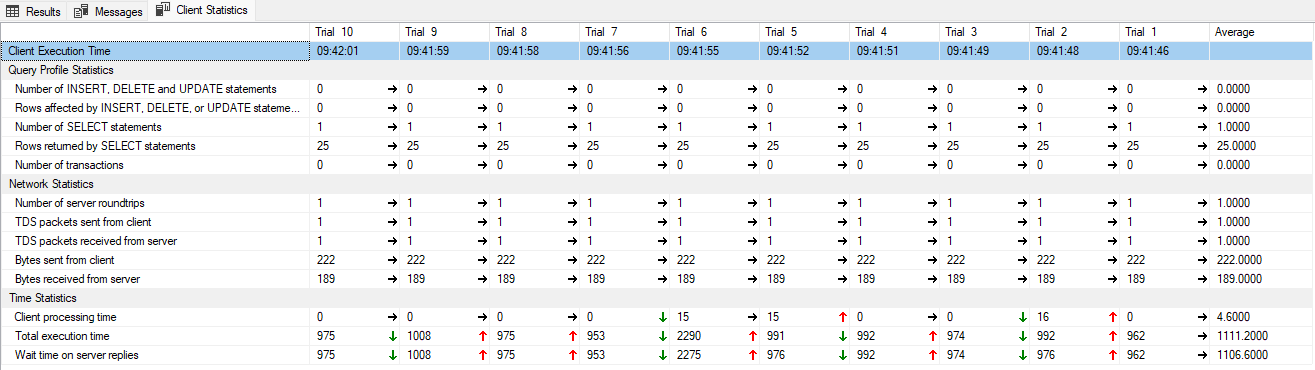
100001.Dzury 3,4,11,801,802,5000,9003,9004,9005,99000,99001,99002,99003,99004,99999,100000
no taka ilość rekordów nie pozwala na dawanie stwierdzeń, że pętle są szybsze.
Jeżeli zwiększymy dane 10 krotnie:
--dane testowe
CREATE TABLE [dbo].[tblTest](
[id] [int] NOT NULL
) ON [PRIMARY]
GO
truncate table [tblTest]
go
with cte as (
SELECT n1.n + 10*n2.n + 100*n3.n + 1000*n4.n + 10000*n5.n + 100000*n6.n lp
FROM (VALUES(0),(1),(2),(3),(4),(5),(6),(7),(8),(9)) n1(n),
(VALUES(0),(1),(2),(3),(4),(5),(6),(7),(8),(9)) n2(n),
(VALUES(0),(1),(2),(3),(4),(5),(6),(7),(8),(9)) n3(n),
(VALUES(0),(1),(2),(3),(4),(5),(6),(7),(8),(9)) n4(n),
(VALUES(0),(1),(2),(3),(4),(5),(6),(7),(8),(9)) n5(n),
(VALUES(0),(1),(2),(3),(4),(5),(6),(7),(8),(9)) n6(n)
)
insert into tblTest
select * from cte where lp > 0
delete from tblTest where id in (3,4,11,801,802,5000,9003,9004,9005,99000,99001,99002,99003,99004,99999,100000,
30,400,110,8013,8302,52000,119003,9004,9005,99000,99001,199002,99003,99004,299999,3100000)
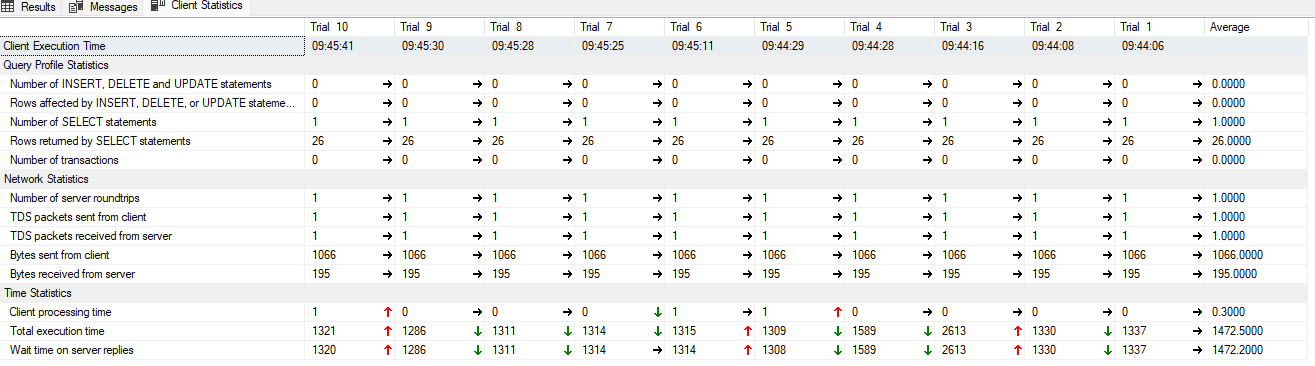
i puścimy twoje rozwiązanie:
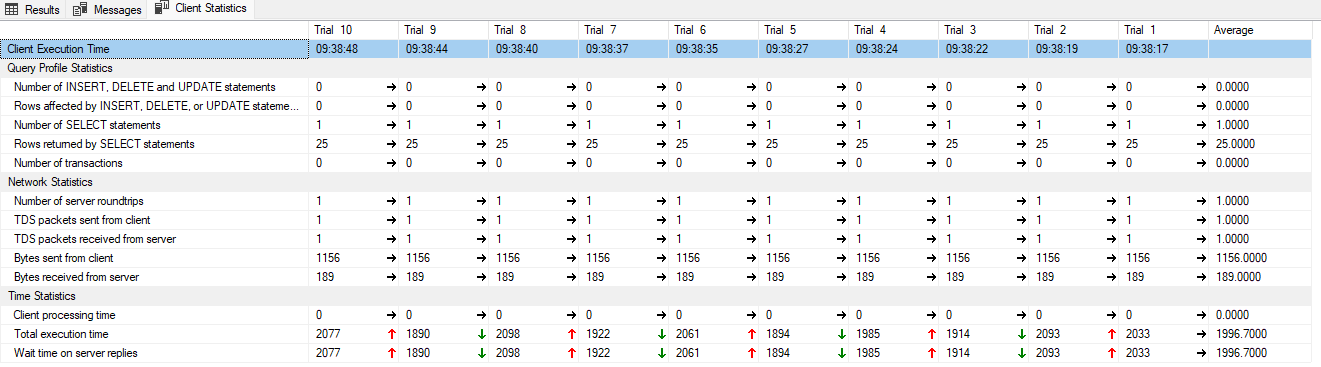
To statystyki wykonania wygladają tak:
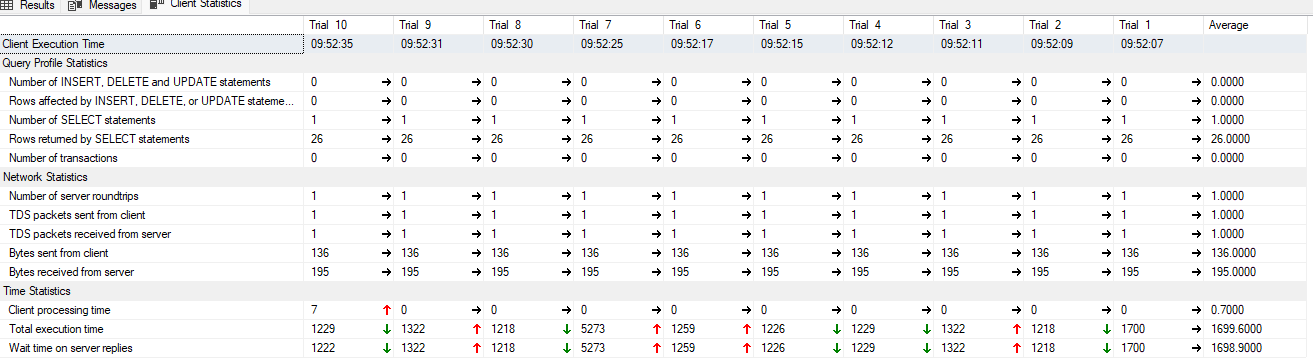
Jeżeli wykonamy to za pomocą selecta:
with cte as (
SELECT
n1.n + 10*n2.n + 100*n3.n + 1000*n4.n + 10000*n5.n + 100000*n6.n lp
FROM (VALUES(0),(1),(2),(3),(4),(5),(6),(7),(8),(9)) n1(n),
(VALUES(0),(1),(2),(3),(4),(5),(6),(7),(8),(9)) n2(n),
(VALUES(0),(1),(2),(3),(4),(5),(6),(7),(8),(9)) n3(n),
(VALUES(0),(1),(2),(3),(4),(5),(6),(7),(8),(9)) n4(n),
(VALUES(0),(1),(2),(3),(4),(5),(6),(7),(8),(9)) n5(n),
(VALUES(0),(1),(2),(3),(4),(5),(6),(7),(8),(9)) n6(n)
)
select lp id from cte lp
left join tbltest t on lp.lp=t.id
where t.id is null
and lp > 0
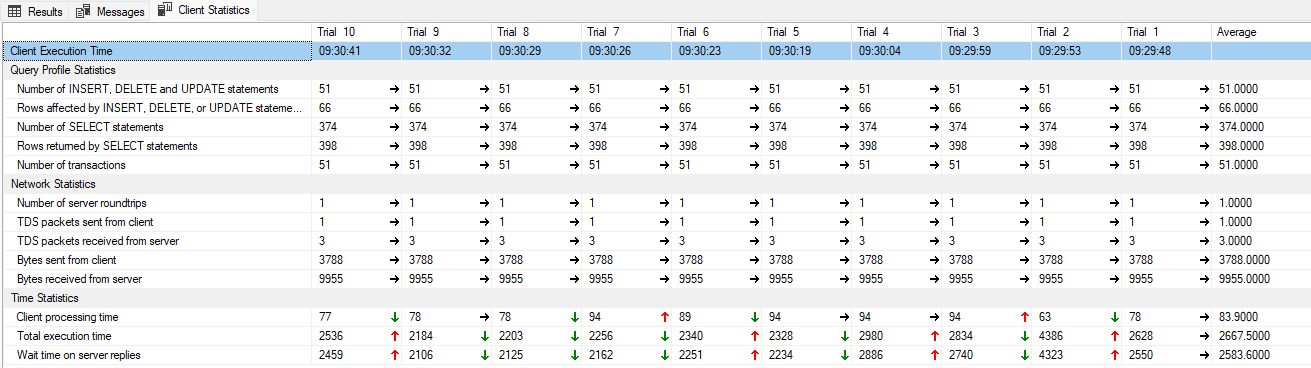
I tak najwięcej tracimy na generowaniu danych, ja osobiście, korzystam z raz wygenerowanej tabeli z kolejnymi numerami, bo taka czasami się przydaje i nie trzeba zapytań do generowania liczb i wtedy schodzimy jeszcze niżej z czasami:
select lp id from nr lp
left join tbltest t on lp.lp=t.id
where t.id is null
and lp > 0