Cześć,
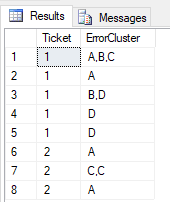
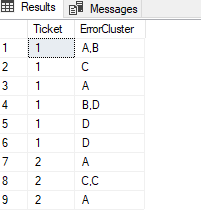
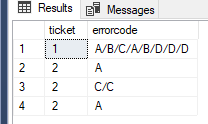
chciałbym z danych z kodu poniżej uzyskać takie pogrupowanie:
Ticket ErrorCluster
1 A / B /C
1 A
1 B / D
1 D
1 D
2 A
2 C / C
2 A
Czyli dla każdego Ticketu zwócić ciąg kodów/ErrorCluster, który będzie ciągiem tylko wtedy jeżeli różnica czasowa między kolejnymi wystapieniami błędu będzie mniejsza niż 10 minut.
W innym wątku rozpatrywałem prostszą wersje tego zadania tzn. że ciąg powstaje dla wszystkich kodów z jednego dnia.
Wyszło w praktyce, że najłatwiej można to zrobić przy pomocy STUFF + For XML Path.
Czy w tej sytuacji można to zrobić podobnie (bardzo skutecznie to działało) czy trzeba iść np. w kursory?
Będę wdzięczny za wszelkie sugestie.
Pozdrawiam,
Arek
DECLARE @table1 TABLE
(
[Ticket] INT,
[ErrorCode] CHAR(1),
[Date] DATETIME
);
INSERT INTO @table1
VALUES
(1, 'A', '01.07.2018 10:00:00'),
(1, 'B', '01.07.2018 10:02:00'),
(1, 'C', '01.07.2018 10:08:00'),
(1, 'A', '01.07.2018 10:30:09'),
(1, 'B', '01.07.2018 10:50:00'),
(1, 'D', '01.07.2018 10:55:00'),
(1, 'D', '01.07.2018 15:55:00'),
(1, 'D', '02.07.2018 10:55:00'),
(2, 'A', '20.10.2018 15:00:00'),
(2, 'C', '20.10.2018 17:00:00'),
(2, 'C', '20.10.2018 17:07:00');
(2, 'A', '21.10.2018 09:00:00');
{kind=link}