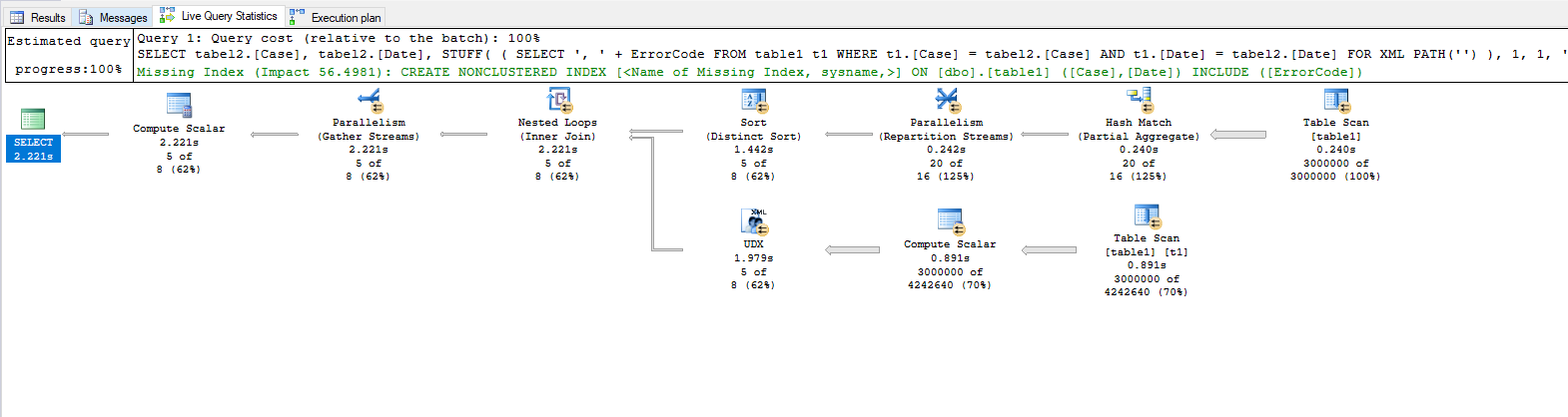
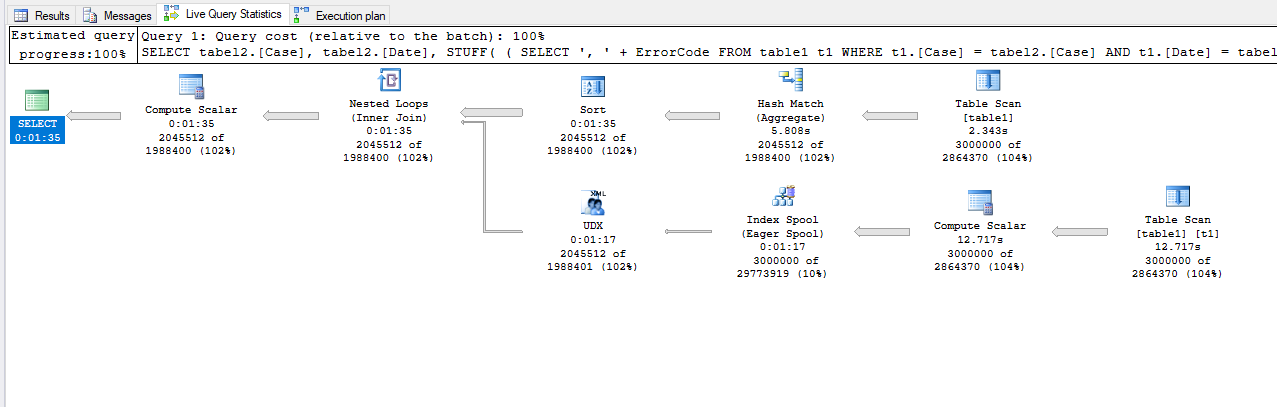
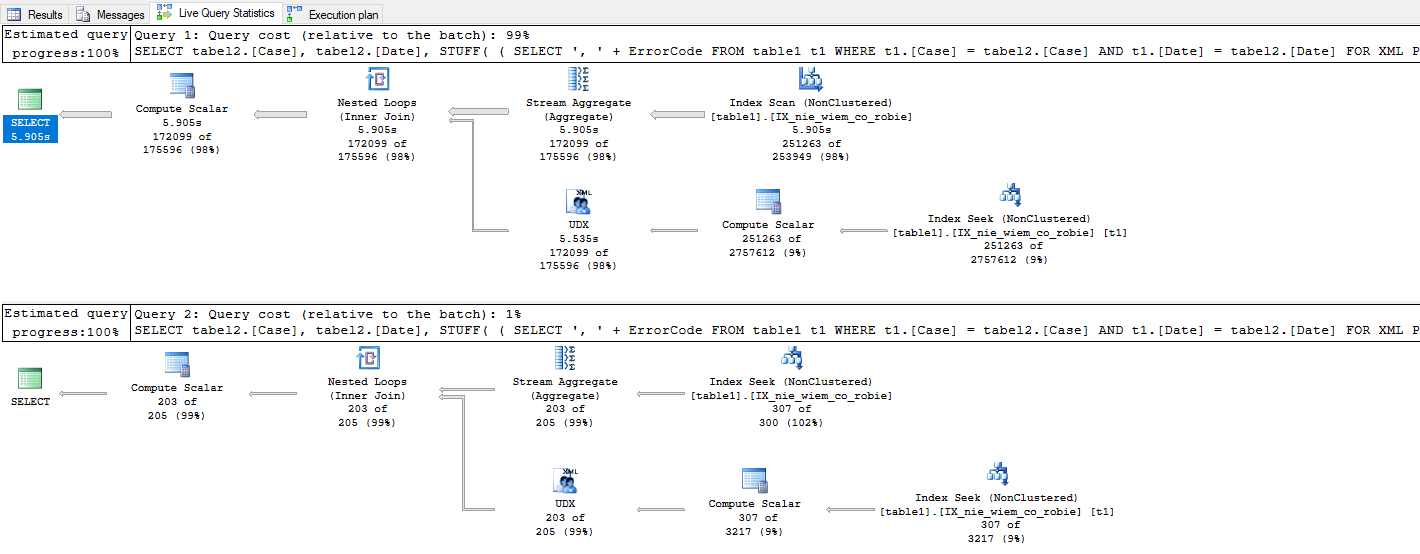
Cześć,
chciałbym uzyskać Table 2 z Table 1.
Czy mogę prosić o jakieś wskazówki jak się do tego najlepiej zabrać?
Pozdrawiam,
A.
**Table 1 **
Case ErrorCode Date
1 A 2018-01-25
1 B 2018-01-15
1 C 2018-01-15
1 A 2018-01-15
1 D 2018-01-15
1 A 2018-01-15
2 D 2018-01-26
2 A 2018-01-26
2 D 2018-01-25
2 D 2018-01-24
2 C 2018-01-24
**Table 2 **
Case Date ErrorCode
1 2018-01-25 A
1 2018-01-15 B / C / A / D A
2 2018-01-26 D / A
2 2018-01-25 D
2 2018-01-24 D / C