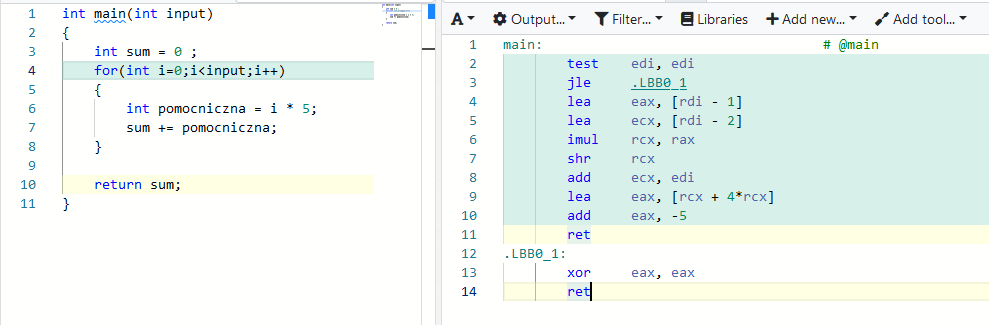
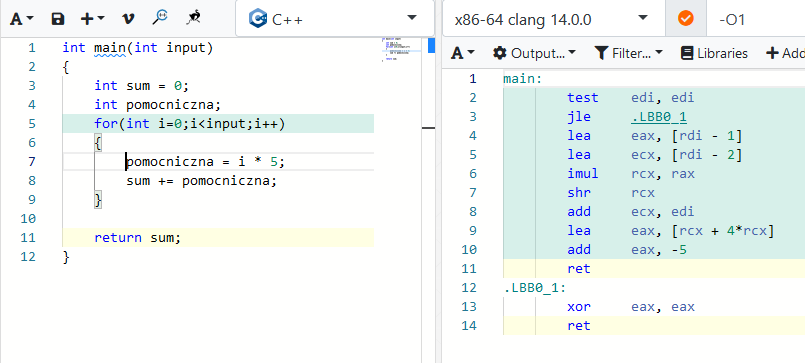
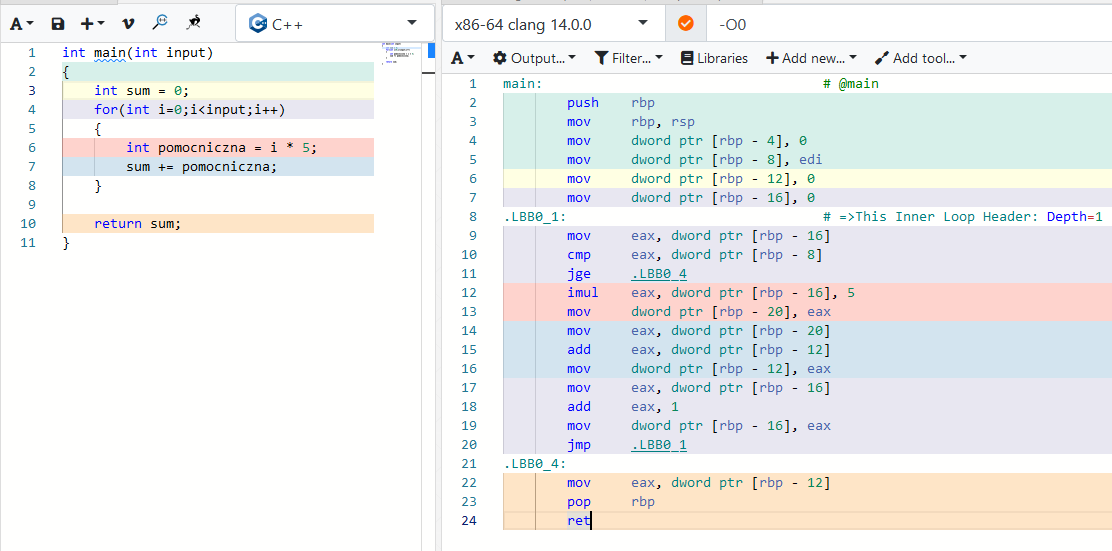
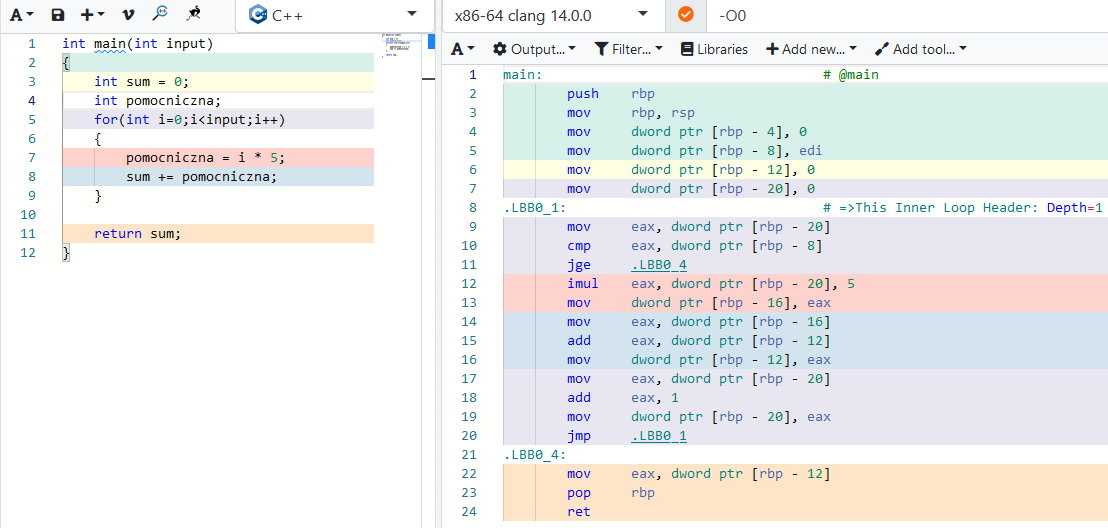
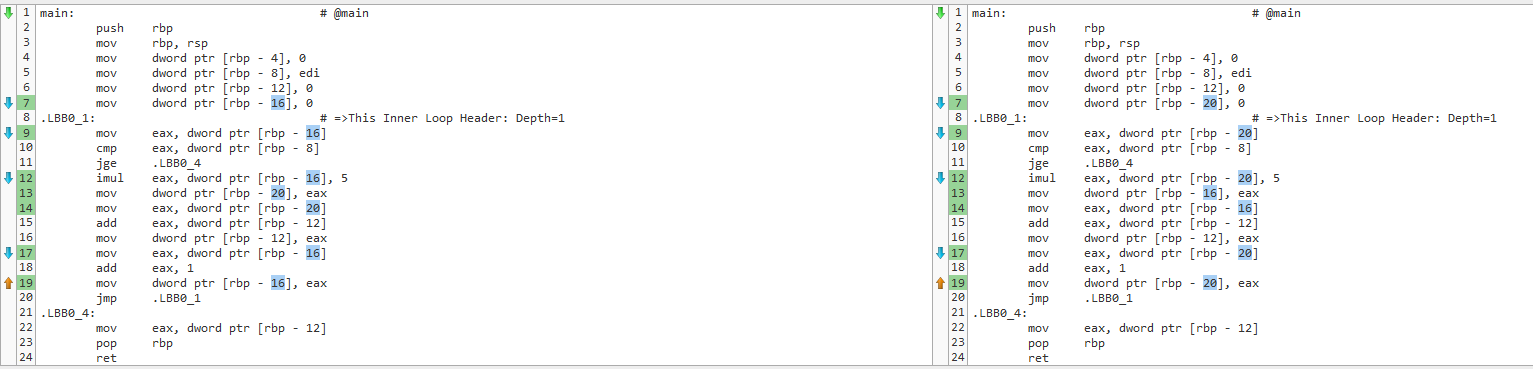
Wszędzie gdzie czytałem uczą że zmienne lokalne są lepsze od globalnych. Ale zastanawiam się co będzie lepsze. Wiem czemu tak piszą i wygoda też ma dla mnie znaczenie ale.
int main()
{
int pomocnicza;
for(int i=0;i<20000000;i++)
{
///////jakiś kod//////////////
//////////////////////////
pomocnicza= zmienna_z_tego_kodu;
//operacje na zmiennej pomocniczej
}
}
//czy
int main()
{
for(int i=0;i<20000000;i++)
{
///////jakiś kod//////////////
//////////////////////////
int pomocnicza= zmienna_z_tego_kodu;
//operacje na zmiennej pomocniczej
}
}
Ponoć zmienne lokalne kiedy kod w nawiasie dobiegnie końca są niszczone i zwalnia miejsce. Wydaje się jakby ze zmeinną lokalną było więcej roboty do wykonania bo trzeba zarezerwować i zwolnić ale mogę się mylić. Widać że musi tu działać jakiś mechanizm który odpowiedzialny jest za sprawdzanie czy dana pamięć jest wolna bo może korzysta z niej inna zmienna. A może kompilator sam rozwiązuje takie problemy i widząc coś takiego postanowi, że zrobi ze zmiennej lokalnej globalną. W innych postach pisali że to coś daje.