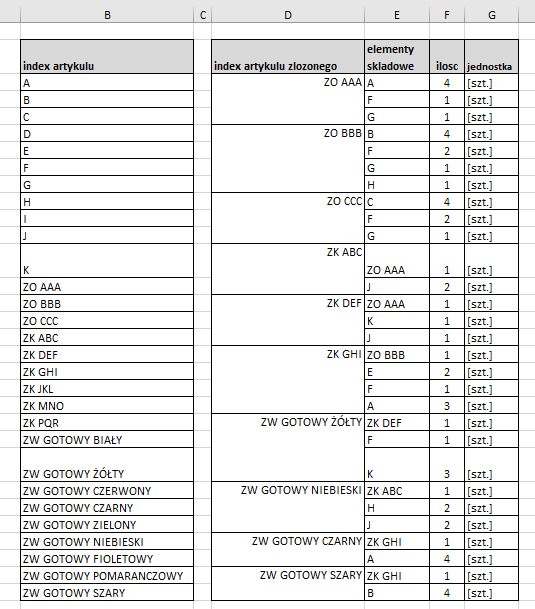
Robie pewne operacje na artykulach w jednym ze swoich podwidokow. Artykuly do tego podwidoku przekazuje z okna glownego. Te artykuly charakteryzuja się tym ze maja w sobie liste materialowa /BOM, bill of materials, recepture - okreslenia na to sa rozne/. W takiej liscie skladowej danego artykulu mogą być materialy proste, polwyroby zlozone ale nie moze byc artykulu samego w sobie.
material prosty - material nie dajacy sie juz bardziej podzielic, ktory nie sklada sie juz z zadnego skladu. (np. srubka, nakretka, korpus obudowy, nozka obudowy, gumowa podkladka nozki itp.)
polwyrob zlozony - polwyrob skladajacy sie z polaczonych paru materialow prostych ale tez moze w sobie zawierac inne polwyroby zlozone np.
powyrob 1 - pakiet przygotowanej/zlozonej nozki obudowy sklada sie z:
- 1szt. nozka obudowy
- 1szt. gumpowa podkladka
- 1sz. srubka
polwyrob 2 - pakiet przygotowanej obudowy uniwersalnej gotowej do zamontowania w sobie customizowanego pod klienta wyposazenia sprzetowego
- 1szt. korpus obudowy
- 4szt. nakretki
- 4szt. polwyrob 1 (przygotowane nozki tylko do przykrecenia nakretka w korpusie obudowy
Poziomow zagniezdzania polwyrobow w wyrobie jest pare i dla kazdego polwyrobu jest roznie, jeden ma jeden poziom, inny 5 poziomow nizej. Im artykul zlozony jest wyzej w hierarchi artykulow tym jest bardziej unikatowy/customizowany, im nizej tym bardziej ogolny. Np. roznych wyrobow gotowych do klientow jest kilkaset, ale typow obudow jest juz tylko kilkanascie, a pakiet nozki jest np. tylko jeden.
Szukam algorytmu wzglednie prostego ktory spelni takie oczekiwania.
- pobierajac do podwidoku jeden dany artykul, automatycznie chce pobierac kazda jego skladową zlozoną /z tym nie mam problemu po prostu smigam rekurencyjnie wglab receptur i pobieram artykuly zlozone/.
- ale jezeli z podwidoku usuwam jeden artykul to chcialbym aby usunac z tego podwidoku rozwniez jegoskladowe zlozone ale tylko takie ktore w tym podwidoku sa czescia tylko tego usuwanego nadrzednego artykulu, nie chce usuwac skladowych ktore sa i w tym usuwanym artykule i sa w innych artykulach juz dodanych do podwidoku.
- w podwidoku wszystkie wybrane artykuly wraz z zawartywi w nich skladowymi wyswietlam tylko raz /bez powtorzen/
- chce generowac linieimportu dla kazdej unikalnej skladowej tylko raz. (nie chce zawalic bazy liniami importu 100sztukami linii dla kazdego pakietu nozki obudowy )
Będe wdzieczny za jakies hasla klucze, jeszcze lepiej za opis jak to realizowac a jak juz bym dostal kawalek kodu to juz w ogóle.
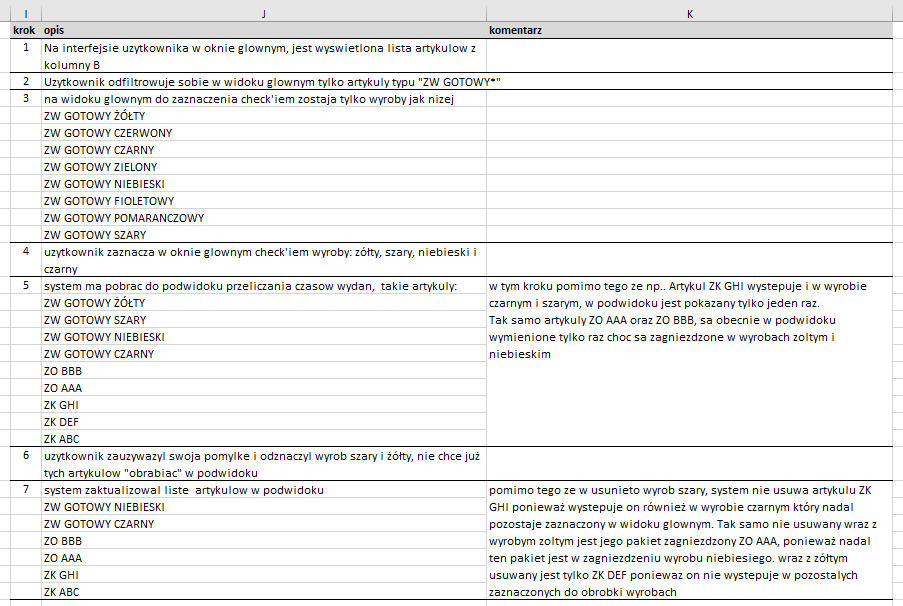
Jezeli cos niejasno opisalem a ktos "mysli patrzac na interfejsc" to w tym watku ponizej umiescilem fragment tego interfejsu.
Konkretnie to co realizuje to, musze wyliczyc czas wydania z magazynu dla kazdego artykulu zlozonego m.in. w oparciu o ilosc skladowych w liscie skladowej w danym artykule.
Podwidok zapewniac ma zmiane nastaw i wizualizacje wynikow wyliczen na zaznaczonej puli artykulow zlozonych.