Cześć,
Mam taki problem. Mam PDFa z raportem i jest w nim dużo tabelek oraz danych nagłówkowych poprzedzających dane w tabelach itp. PDF jest przeszukiwalny. Po zaznaczeniu całego tekstu (czy odczytaniu go itextem) otrzymuję 100% treści, ale zbitej do jednej kupy. Poniżej załączam zanonimizowany przykład - raport BIK (pliki mam różne, z różnych systemów, bez dostępu do API tych systemów)
Czy istnieją jakieś narzędzia, które przyspieszą strukturyzowanie tych danych? W sensie przywrócą tabele, pozwolą jakoś szybko się do nich odnosić (poszczególnych komórek). Wiem, że mogę to zacząć robić np. regexem, ale jest z tym dużo dłubaniny. Można przepuścić taki dokument przez jakiś zaawansowany OCR, ucząc go wcześniej szablonu tego dokumentu, ale zakładam, że OCR może popełnić błąd, a zaznaczenie tekstu nigdy oraz tego typu OCR to po prostu drogie rozwiązanie.
Czemu te dane chcę strukturyzować? Bo taki raport może mieć parędziesiąt stron i chcę te dane później przetwarzać, np. wypluć info o sumie wszystkich kredytów z instytucji BANK BANK, albo łącznej ilość dni opóźnienia dla wszystkich kredytów itd.
Szukam narzędzia/sposobu, o którym może nie wiem, że w ogóle istnieje.
Plik:
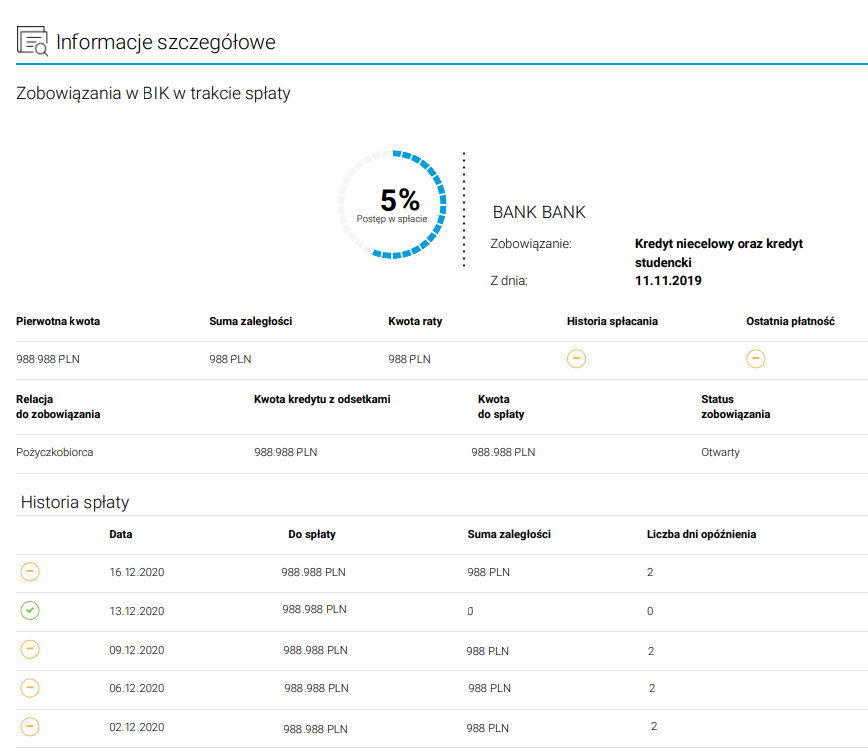
To co odczytuje z niego np. itextem:
Informacje szczegółowe
BANK BANK
Zobowiązanie: Kredyt niecelowy oraz kredyt
studencki
Z dnia: 11.11.2019
Pierwotna kwota Suma zaległości Kwota raty Historia spłacania Ostatnia płatność
988.988 PLN 988 PLN 988 PLN
Relacja
do zobowiązania
Kwota kredytu z odsetkami Kwota
do spłaty
Status
zobowiązania
Pożyczkobiorca 988.988 PLN 988.988 PLN Otwarty
Historia spłaty
Data Do spłaty Suma zaległości Liczba dni opóźnienia
16.12.2020 988.988 PLN 988 PLN 2
13.12.2020 988.988 PLN 0 0
09.12.2020 988.988 PLN 988 PLN 2
06.12.2020 988.988 PLN 988 PLN 2
02.12.2020 988.988 PLN 988 PLN 2