Mam takie zadanie:
Bajtocja
Limit pamięci: 32 MB
Za górami, za lasami, za rzekami, za morzami leży kraj potężny i bogaty zwany Bajtocją. Panuje tam dobrotliwy król Bajtazar I Wielki, słynny ze swej troski o infrastrukturę kraju. W Bajtocji znajduje się miast. Władca rozkazał swym nadwornym architektom przygotować projekty nowych ponaddźwiękowych traktów konnych. Jako odpowiedź otrzymał propozycji, każda z nich składa się z trzech liczb p, k, w, gdzie p i k są miastami końcowymi traktu (trakt łączy te miasta bezpośrednio i nie przebiega przez inne miasta), a oznacza koszt zbudowania tego traktu. Każdym traktem można podróżować zarówno z miasta do , jak i w stronę przeciwną. Zamierzeniem króla jest budowa sieci traktów w taki sposób, aby można było nimi przejechać między każdymi dwoma miastami, być może odwiedzając po drodze inne miejscowości. Bajtazar jest bardzo oszczędnym królem, więc postanowił zgodzić się tylko na taką sieć, która będzie możliwie najtańsza.
Zadanie
Opracuj program, który:
wczyta ze standardowego liczbę miast, liczbę proponowanych traktów oraz opisy tych traktów,
dla każdego traktu określi, czy istnieje taka sieć połączeń między miastami, zgodna z królewskimi rozkazami i w której rozpatrywany trakt, wybudowany za wskazaną kwotę, jest wykorzystywany,
wypisze na standardowe wyjście zestawienie uzyskanych wyników.
Wejście
Pierwszy wiersz wejścia zawiera dwie liczby całkowite: liczbę miast n i liczbę proponowanych traktów m, rozdzielone pojedynczą spacją i spełniające warunki 2 <= n <= 7.000, 1<=m<=300.000 . Każdy z kolejnych wierszy zawiera po trzy liczby całkowite p, k, w rozdzielone pojedynczymi spacjami, opisujące proponowany trakt, przy czym p i k oznaczają miasta będące końcami traktu, zaś w jest ceną budowy tego traktu (1 <= p, k <= n, 1 <= w <= 100.000 ).
Wyjście
W każdym z kolejnych wierszy należy wypisać słowo "TAK" albo "NIE", w zależności od tego, czy można skonstruować plan budowy zgodny z życzeniem króla, dla którego trakt opisany w odpowiednim wierszu jest w nim zawarty. Możesz bezpiecznie założyć, że dla danych wejściowych zawsze istnieje plan budowy spełniający wymogi Bajtazara.
Przykład
Dla danych wejściowych:
6 10
1 2 2
1 6 1
1 5 3
4 1 5
2 6 2
2 3 5
4 3 4
3 5 4
4 5 4
5 6 3
poprawną odpowiedzią jest:
TAK
TAK
TAK
NIE
TAK
NIE
TAK
TAK
TAK
TAK
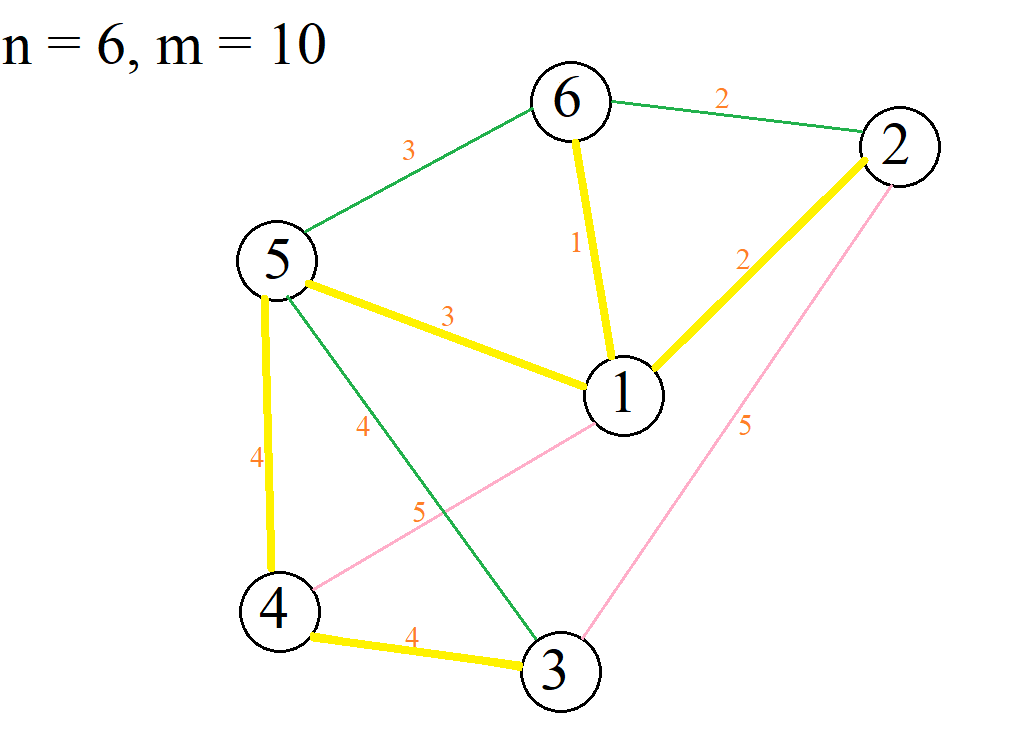
Narysowałem ten graf (różowe węzły to te trakty których król nie chce zbudować)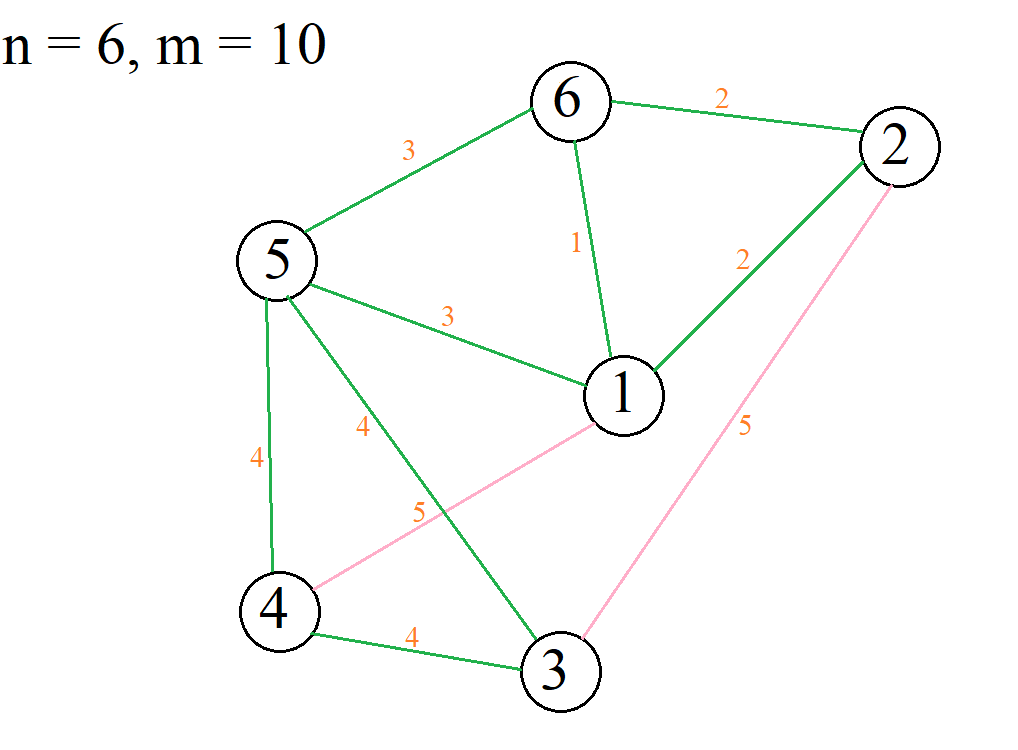
Skoro Król chce najtańszą sieć dróg to po co np. buduje tyle połączeń z pierwszym miastem ? Przecież wystarczyłoby jedno
LINK DO ZADANIA
TUTAJ TESTUJE