Witam.
Staram się sklecić w miarę wydajny ale też szybki algorytm do skalowania bitmap.
W przypadku powiększania (upscaling) mój wybór padł na interpolację dwuliniową (bilinear), bo po prostu daje niezłe efekty niewielkim kosztem. Nie aż tak dobre jak bicubic, ale przy tym nie jest aż tak wymagająca obliczeniowo. Wydaję mi się, że wszystko robię dobrze, ale jedna rzecz nie daje mi spokoju, więc wyjaśnię po krótce o co chodzi (w przykładzie posłużę się "obrazem" 1D, złożonym z poziomej linii - tak dla ułatwienia).
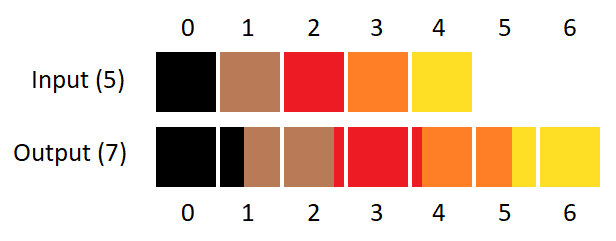
Załóżmy, że mam obraz o szerokości 5, a chciałbym go przeskalować do szerokości 7. Najpierw muszę sobie wyliczyć współrzędne nowych pikseli względem tych pierwotnych.
R = nowa wielkość / oryginalna wielkość = 5/7 = 0,7142
Współrzędna X piksela z obrazu końcowego na obrazie pierwotnym = Współrzędna X piksela obrazu końcowego * R
Czyli kolejno:
X(0) = 0 * R = 0 (kopia piksela 0 z obrazu pierwotnego)
X(1) = 1 * R = 0,7142 (sub-piksel interpolowany pomiędzy pikselem 0 i 1)
X(2) = 2 * R = 1,4284 (sub-piksel interpolowany pomiędzy pikselem 1 i 2)
X(3) = 3 * R = 2,1426 (sub-piksel interpolowany pomiędzy pikselem 2 i 3)
X(4) = 4 * R = 2,8568 (sub-piksel interpolowany pomiędzy pikselem 2 i 3)
X(5) = 5 * R = 3,571 (sub-piksel interpolowany pomiędzy pikselem 3 i 4)
X(6) = 6 * R = 4,2852 (sub-piksel interpolowany pomiędzy pikselem 4 i 5)
Z powyższego wychodzi, że pierwszy piksel końcowego obrazu zawsze jest po prostu kopią pierwszego piksela z obrazu pierwotnego (bo cokolwiek pomnożone przez zero, zawsze da zero), natomiast wszystkie inne piksele są sub-pikselami leżącymi gdzieś na granicy dwóch pikseli pierwotnego obrazu. Tak powinno być? To niby nic wielkiego ale jakoś mi ten pierwszy piksel nie pasuje.