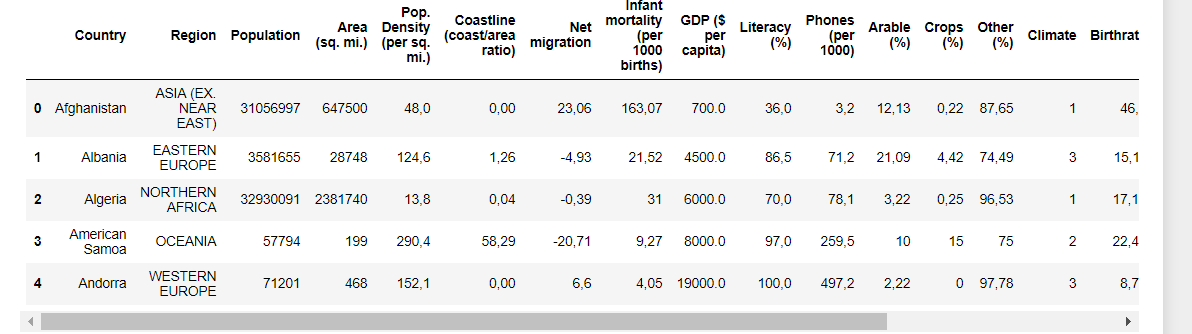
Cześć, mam problem. Po zaimportowaniu danych( data) chciałem podzielić je przy pomocy k-średnich. W celu znalezienia optymalnego K zastosowałem metryke calinski_harabasz, lecz wychodzi mi, że optymalne K to 70 000 tyś. Jak myślicie gdzie tkwi problem. Na początku przygotowałem dane, usunąłem przecinki i przygotowałem na format liczbowy (dane były w pliku csv).
0
0
0
quantity=[]
celinsky=[]
for i in range(2,40):
clasters = KMeans(n_clusters=i)
quantity.append(i)
clasters.fit(data)
labels = clasters.labels_
celinsky.append(metrics.calinski_harabasz_score(data, labels))
plt.subplot(2, 1, 1)
plt.plot(quantity, celinsky, '-', lw=2)
0
2 pierwsze kolumny też zostały odrzucone
0
K średnie operują na różnicy odległości między N-wymiarowymi punktami. Może warto dane znormalizowac przed zaaplikowaniem algorytmu? Populacja ma duże wartości bezwzględne, które mogą zabijać różnice na dalszych pozycjach wektorów wejściowych.
Nie wiem jak wygląda wspomniana metryka i implementacja k-means w pythonie, wiec sugestia o normalizacji może być nieistotna, bo np. Implementacja o to dba...
0
Jakie wymiary ma macierz danych, którą wrzucasz w pętlę for? Dodatkowo, czy chcesz wyliczyć K indywidualnie dla każdej kolumny?