Siemka,
miałem do zrobienia aktualizację wartości w jednej liście bazując na innej, aby wykonać tą operację użyłem streamów. Następnie nadeszła optymalizacja i zrodziło się pytanie, o ile to jest szybsze, a może tylko ładniej wygląda. Kiedyś słyszałem gdzieś o micro benchmarkach to czemu nie spróbować i oto me dzieło:
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.Setter;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.infra.Blackhole;
import java.math.BigDecimal;
import java.util.*;
import java.util.concurrent.TimeUnit;
import java.util.function.Function;
import java.util.stream.Collectors;
@Fork(1)
@Warmup(iterations = 10)
@Measurement(iterations = 10)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class UpdateObjectInOneListBasedOnSecondOne {
@AllArgsConstructor
@Getter
@Setter
public static class BookOverallData {
private Long idOfBook;
private String title;
private String authour;
private BigDecimal basePrice;
private Integer discountRate;
}
@AllArgsConstructor
@Getter
public static class TimeDiscount {
private Long idOfBook;
private Integer discountRate;
}
private Set<BookOverallData> getListWithBooks(){
return Set.of(new BookOverallData(1L, "1984", "George Orwell", BigDecimal.valueOf(25.6), 10),
new BookOverallData(2L, "Sentimental Education", "Gustave Flaubert", BigDecimal.valueOf(12.3), 0),
new BookOverallData(3L, "Absalom, Absalom!", "William Faulkner", BigDecimal.valueOf(32.62), 30),
new BookOverallData(4L, "The Hunger Games", "Suzanne Collins", BigDecimal.valueOf(12.45), 40),
new BookOverallData(5L, "To Kill a Mockingbird", "Harper Lee", BigDecimal.valueOf(10.6), 10),
new BookOverallData(6L, "Pride and Prejudice", "Jane Austen", BigDecimal.valueOf(15.4), 0),
new BookOverallData(7L, "The Book Thief", "Markus Zusak", BigDecimal.valueOf(9.99), 15),
new BookOverallData(8L, "Animal Farm", "George Orwell", BigDecimal.valueOf(22.0), 24),
new BookOverallData(9L, "Gone with the Wind", "Margaret Mitchell", BigDecimal.valueOf(12.4), 27),
new BookOverallData(10L, "The Fault in Our Stars", "John Green", BigDecimal.valueOf(16.00), 17),
new BookOverallData(11L, "The Giving Tree", "Shel Silverstein", BigDecimal.valueOf(19.99), 15),
new BookOverallData(12L, "Wuthering Heights", "Emily Brontë", BigDecimal.valueOf(20.0), 11),
new BookOverallData(13L, "The Da Vinci Code", "Dan Brown", BigDecimal.valueOf(10.0), 7),
new BookOverallData(14L, "Memoirs of a Geisha", "Arthur Golden", BigDecimal.valueOf(45.0), 4),
new BookOverallData(15L, "The Picture of Dorian Gray", "Oscar Wilde", BigDecimal.valueOf(23.99), 16),
new BookOverallData(16L, "Les Misérables", "Victor Hugo", BigDecimal.valueOf(12.00), 24),
new BookOverallData(17L, "Jane Eyre", "Charlotte Brontë", BigDecimal.valueOf(55.99), 12),
new BookOverallData(18L, "Lord of the Flies", "William Golding", BigDecimal.valueOf(24.00), 6),
new BookOverallData(19L, "Crime and Punishment", "Fyodor Dostoyevsky", BigDecimal.valueOf(17.55), 0),
new BookOverallData(20L, "The Perks of Being a Wallflower", "Stephen Chbosky", BigDecimal.valueOf(15.99), 0));
}
private Set<TimeDiscount> getListWithDiscounts(){
return Set.of(new TimeDiscount(1L, 20), new TimeDiscount(8L, 20), new TimeDiscount(19L, 20));
}
@Benchmark
public void usedForLoop() {
final Set<BookOverallData> listWithBooks = getListWithBooks();
final Set<TimeDiscount> listWithDiscounts = getListWithDiscounts();
for (BookOverallData bookOverallData : listWithBooks){
for (TimeDiscount timeDiscount : listWithDiscounts){
if (timeDiscount.getIdOfBook().equals(bookOverallData.getIdOfBook())){
bookOverallData.setDiscountRate(timeDiscount.getDiscountRate() + bookOverallData.getDiscountRate());
}
}
}
Blackhole.consumeCPU(10);
}
@Benchmark
public void streamOfStream() {
final Set<BookOverallData> listWithBooks = getListWithBooks();
final Set<TimeDiscount> listWithDiscounts = getListWithDiscounts();
listWithBooks.forEach(
p -> {
final Optional<TimeDiscount> promotion = listWithDiscounts.stream().filter(ap -> Objects.equals(ap.getIdOfBook(), p.getIdOfBook())).findFirst();
promotion.ifPresent(ap -> p.setDiscountRate(ap.getDiscountRate() + p.getDiscountRate()));
}
);
Blackhole.consumeCPU(10);
}
@Benchmark
public void streamOptimized() {
final Set<BookOverallData> listWithBooks = getListWithBooks();
final Set<TimeDiscount> listWithDiscounts = getListWithDiscounts();
Map<Long, TimeDiscount> accumulator =
listWithDiscounts.stream()
.collect(Collectors.toMap(TimeDiscount::getIdOfBook, Function.identity()));
listWithBooks.forEach(e ->
Optional.ofNullable(accumulator.get(e.getIdOfBook()))
.ifPresent(p -> e.setDiscountRate(e.getDiscountRate() + p.getDiscountRate()))
);
Blackhole.consumeCPU(10);
}
}
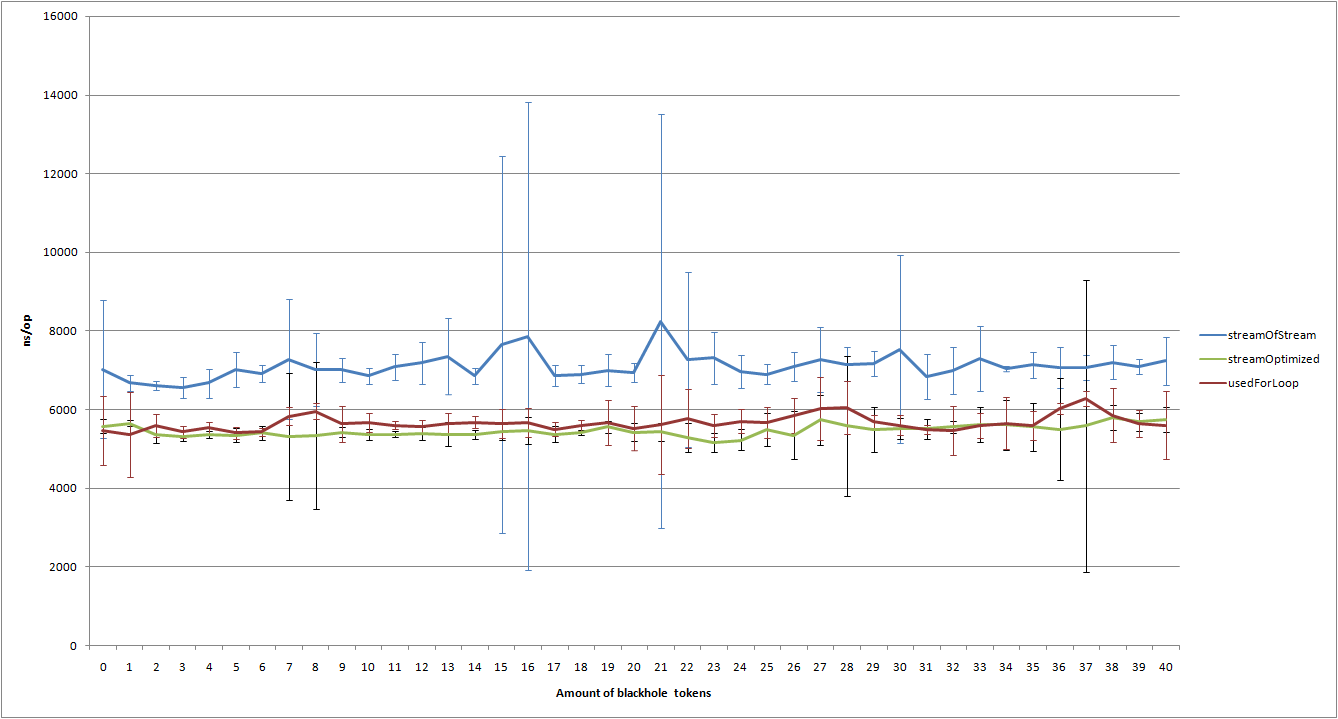
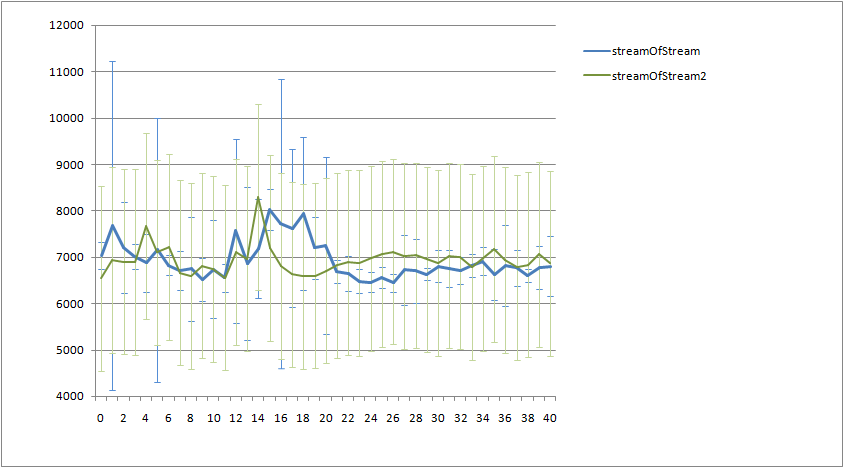
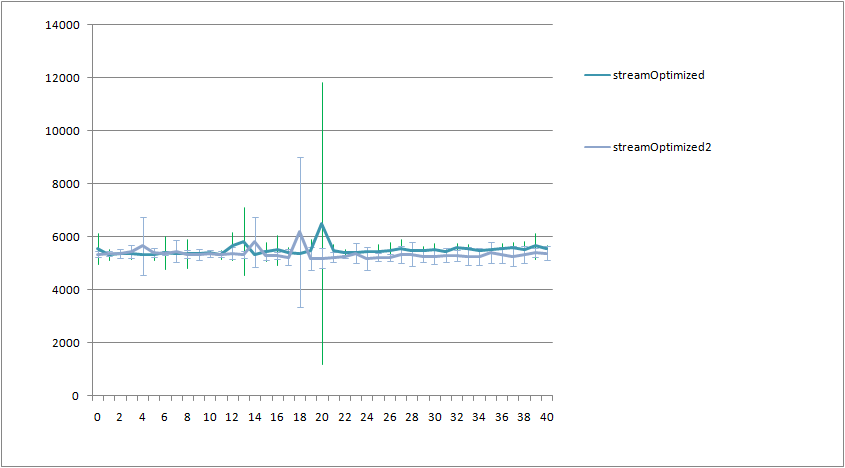
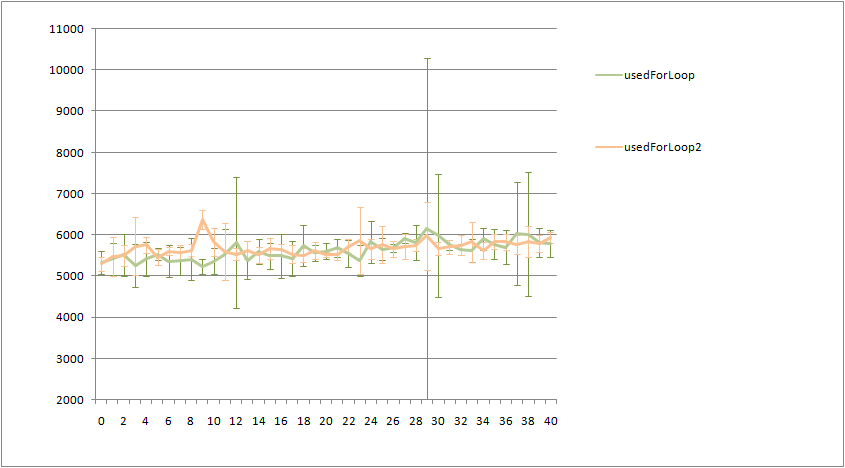
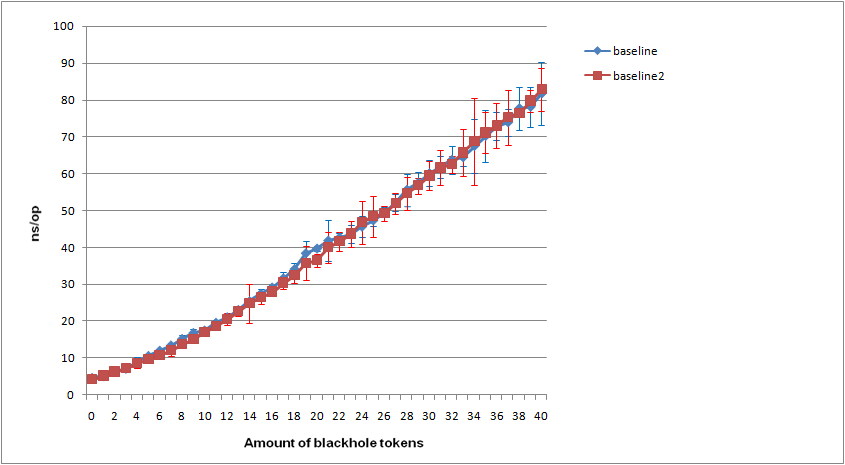
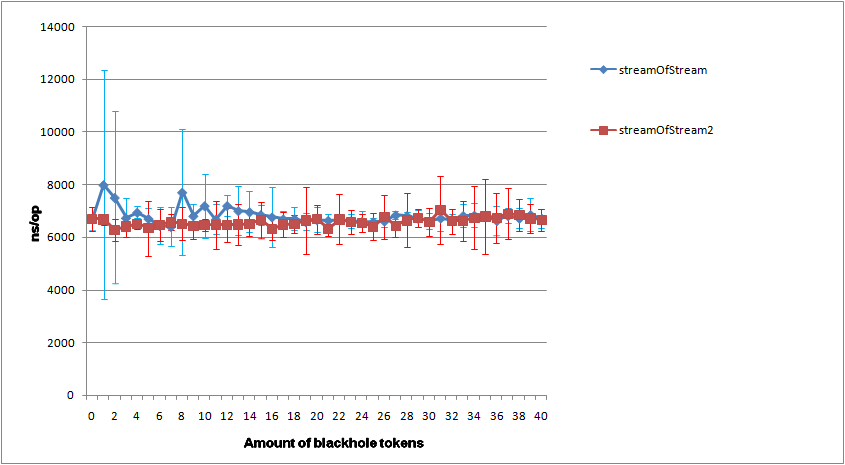
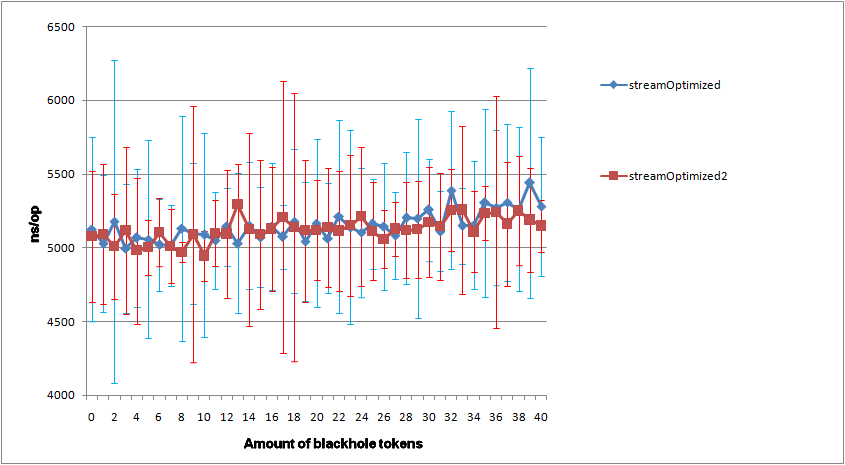
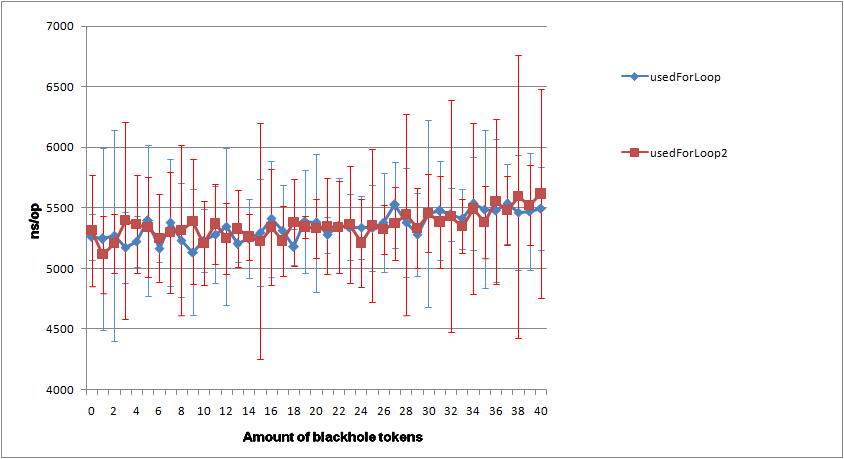
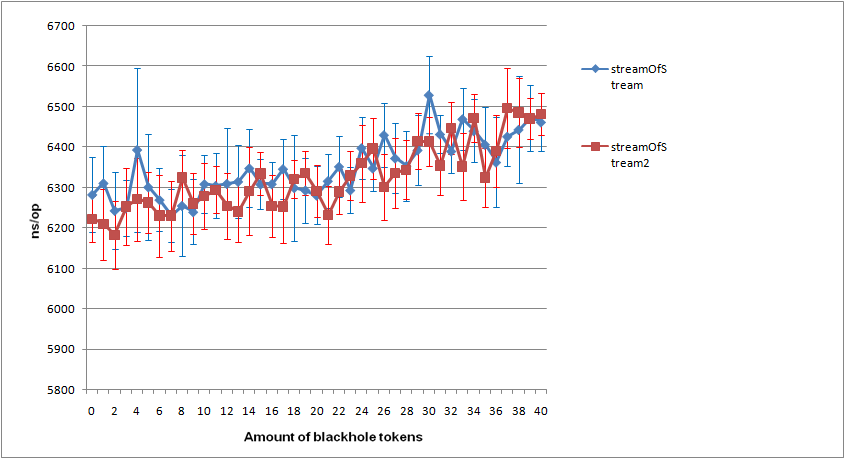
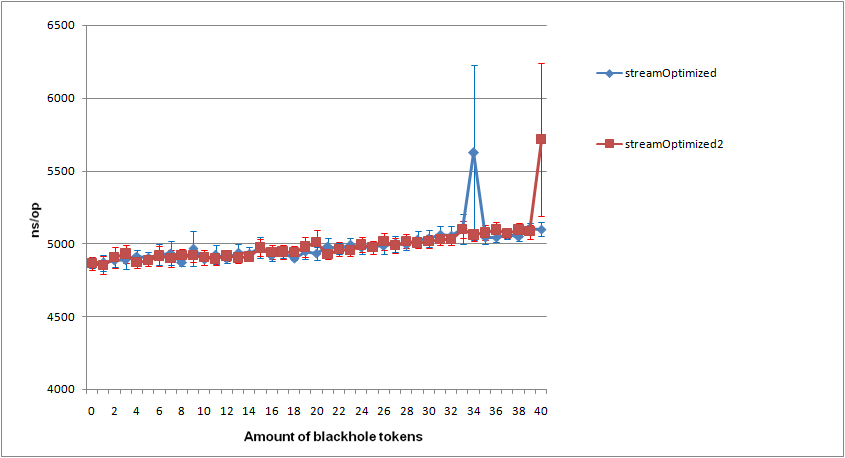
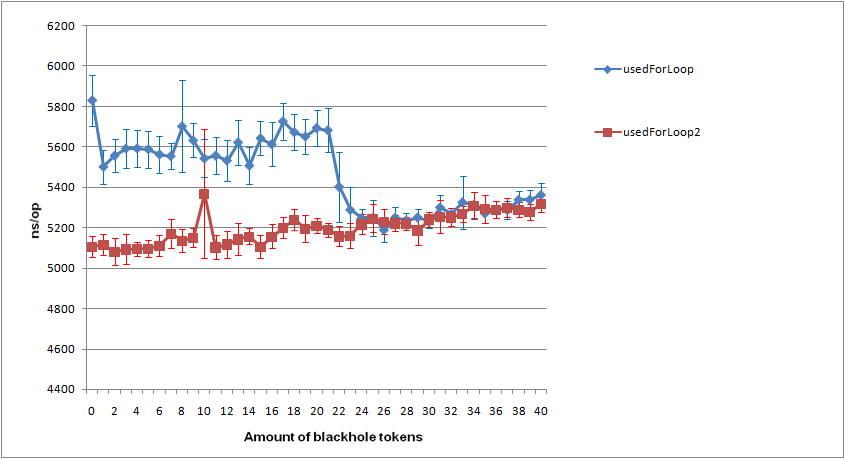
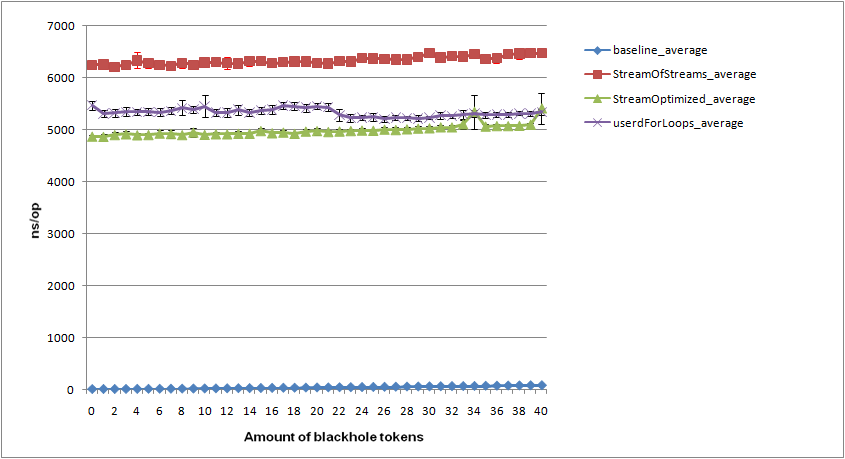
W benchmarku wyszło, że zoptyamlizowane streamy są szybsze od tych pierwotnych, biorąc pod uwagę , że nie tworzę streama stremow dla każdego elementu, to składa się to w jedną całość.
Do benchmarku używam JMH. Dorzucam logi testu w załączniku.
Moje pytanie jest następujące, co można zmienić/dodać aby test był jeszcze bardziej wiarygodny?