Znajdowanie reguł w probabilistycznych zbiorach liczb całkowitych. / Finding rules in probablistic datasets of integer numbers.
Jeden z dwóch artykułów poświęconych sztucznej inteligencji. Artykuł dotyczy znajdowania reguł w zbiorach danych w C# i SQL. Drugi artykuł dotyczy systemów eksperckich. Link do drugiego artykułu znajduje się w części B. One of two articles concerning artificial intelligence. This one presents finding rules in data sets using C# and SQL and is a pair with one about expert systems. You can find the link to the second one in part B.
***
-
Uwaga:
-
Jeśli nie chcesz tego czytać, a zobaczyć, jak to działa, pobierz pełny spakowany (.zip) projekt C# z kodem źródłowym, klikając tutaj DataMiner.zip
-
Projekt można również pobrać w punkcie D.2.1, jeśli nie interesuje cię rozwiązanie w SQL.
Treść udostępniona na zasadach licencji Creative Commons Attribution -
Autor uznaje również załączony projekt C# za integralną część poniższego artykułu i rezerwuje sobie prawo do modyfikacji tego projektu na rzecz poprawienia jego jakości bez dokonywania zmian w poniższym artykule, w szczególności bez informowania czytelników o tym fakcie.
-
Note:
-
If you do not want to read it, but you want to see how it works, please, download full zipped C# project with enclosed source code by clicking here DataMiner.zip
-
You can also download project in point D.2.1 if you are not interested in SQL solution.
Content shared under license Creative Commons Attribution -
Author also considers enclosed C# project as integral part of article below, and reserves himself the right to modify this project for purposes of increasing its quality without making changes to the rest of article, especially without informing readers about this fact.
A. Wstęp / Introduction
A.1 Cel i struktura artykułu / Purpose and structure of article
| A.1 Cel i struktura artykułu | A.1 Purpose and structure of article |
|---|---|
| Celem tego artykułu jest przybliżenie samego pojęcia szukania reguł w danych. | Purpose of this article is to introduce concept of searching rules in data. |
| Dla mnie termin ten brzmiał bardzo tajemniczo, dopóki nie napisałem programu. | For me this term sounded very mysterious until I wrote my program. |
| Tu prezentuję już rezultat, który dało dopiero porównanie, tak naprawdę, kilku programów, które powstały po drodze. | Here I present result that was achieved by comparing, in fact, number of programs which were created along my way. |
| Myślę, że do programistów najlepiej przemówi działający program i jego kod. | I think for most developers running program and its code can speak better. |
| Pierwszą część artykułu poświęcam temu, jak w ogóle się do tego zabrać. | First part of article I dedicate this, as in general to go about it. |
| Pokazuję sposób na weryfikację poprawności algorytmu szukania reguł w danych w C# | I show solution in C# - a method for verification of correctness of algorithm searching rules in data. |
| W dalszej części jest opisane bardzo efektywne rozwiązanie w SQL. | Following part describes very effective solution in SQL. |
A.1.1 Symetria danych / Data symmetry
| A.1.1 Symetria danych | A.1.1 Data symmetry |
|---|---|
| Dla potrzeb prezentacji wykorzystałem funkcje generujące zbiory danych, w których występują w mniejszym lub większym stopniu symetrie między danymi. | For presentation purposes I used functions to generate data sets where there is greater or lesser degree of symmetry between data. |
| Zainteresowanych tym tematem odsyłam do linku poniżej, który opisuje zagadnienie z zakresu chemii. | For those who is interested in this topic I refer to link below for domain of chemistry. |
| Uznałem, że to najlepszy model wzięty z rzeczywistości naukowców, niemniej wykraczający poza ramy tego artykułu. | I think it is the best model taken from scientists reality, but going beyond scope of article. |
Po polsku / Polish
Symetria cząsteczkowa, Wikipedia
Po angielsku / English
Molecular symmetry, Wikipedia
A.2 Czym jest ekstrakcja reguł z danych? / What is to extract rules from data?
| A.2 Czym jest ekstrakcja reguł z danych? | A.2 What is to extract rules from data? |
|---|---|
| Ekstrakcja reguł z danych jest częścią szerszego zagadnienia, jakim jest Data Mining. | Extraction of rules from data is part of broader issue, which is Data Mining. |
| Jej celem jest znajdowanie w danych reguł, które są czasami ukryte dla człowieka. | Its purpose is to find rules that are hidden from man sometimes. |
| Ukryte reguły inaczej można nazwać ukrytą wiedzą. | Hidden rules shall otherwise be called hidden knowledge. |
| Zwykle człowiek posiada jakąś wiedzę o zależnościach między danymi. | Usually man has some knowledge about relationships between data. |
| Jeżeli są to dane ekonomiczne, ekonomista będzie wiedział, jakie są oczywiste zależności między zatrudnieniem, cenami materiałów i kosztami produkcji, podażą, popytem, ceną produktu, jego jakością, sprzedażą i zyskiem. | Having economic data, economist will know what are obvious relationships between employment, prices, materials and production costs, supply, demand, price of product, its quality, sales and revenue. |
| Podobnie jest z naukowcem szukającym nowego leku. | Similarly, scientist looking for a new medicine. |
| Wiele leków już istnieje. Mają swoje znane składniki, znane metody syntezy związków chemicznych i pomagają na określone choroby, które z kolei mają swoje objawy. | Many medicines already exist. They have known components, known methods of synthesis of chemical compounds and help to certain diseases, which have their symptoms. |
| Posiadając takie dane naukowiec może postawić pytanie: czy lek lub grupa leków, które pomagają na jedną chorobę, pomoże w leczeniu innej choroby? | With this data, the researcher may ask the question: whether well known medicine or class of medicines that helps one disease, would help in treatment of other diseases? |
| Pojawia się jednak problem. Danych jest bardzo dużo. | However, there is a problem. Set of data is very large. |
| Podobną sytuację spotyka ekonomista, zwłaszcza w dużej organizacji biznesowej, jak i naukowiec. | Similar situation is encountered by economist, especially in large business organization and by scientist. |
| Obaj analizują dane z wielu lat lub porównują wyniki różnych oddziałów firmy, czy też wyniki badań różnych zespołów naukowców, nawet w krótkim okresie. | Both analyze data from multiple years, or compare results of different branches of company, or results of different research teams, even in a short term. |
| Komputer może znaleźć zależności między odległymi faktami, z czym człowiek ma już problem. | Computer is able to find relationships between distant facts what is a problem for man. |
| Człowiek może zadać model reguł, które go interesują. | Man can set a model of rules, which interests him. |
| Tym samym stawia hipotezy, że w ogóle pewne zależności istnieją. | This way man tries hypotheses concerning relationships that maybe exist. |
| Komputer pomaga człowiekowi w sprawdzeniu hipotez. | Computer helps man in verification of hypotheses. |
A.3 Istota stawiania hipotez i doboru reprezentatywnych zbiorów danych / Essence of hypotheses and selection of representative data sets
| A.3 Istota stawiania hipotez i doboru reprezentatywnych zbiorów danych | A.3 Essence of hypotheses and selection of representative data sets |
|---|---|
| Zanim przejdę do właściwego programu, spójrzmy na poniższy algorytm na dwa sposoby: | Before I get into the right program let's look at the following algorithm in two ways: |
using System;
using System.Collections;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
ArrayList Rules = new ArrayList();
//---------- ---------- ---------- ----------
#region Reguły / Rules
#region Hipotezy / Hypothesis
Rules.Add("rule 1");
Rules.Add("rule 2");
#endregion Hipotezy / Hypothesis
Rules.Add("rule 3");
Rules.Add("rule 4");
// itd. / etc.
// ...
// Rules.Add("rule 1.000.000");
#endregion Reguły / Rules
//---------- ---------- ---------- ----------
#region Wektory / Vectors
#region Reprezentatywne próbki / Representative samples
ArrayList Vectors = new ArrayList();
Vectors.Add("vector 1");
Vectors.Add("vector 2");
#endregion Reprezentatywne próbki / Representative samples
Vectors.Add("vector 3");
Vectors.Add("vector 4");
// itd. / etc.
// ...
// Vectors.Add("vector 1.000.000")
#endregion Wektory / Vectors
//---------- ---------- ---------- ----------
for (int i = 0; i < Rules.Count; i++)
{
for (int j = 0; j < Vectors.Count; j++)
{
// Sprawdzenie prawdziwości reguły {0} dla wektora {1}
// Checking accuracy of rule {0} for vector {1}
Console.WriteLine("{0} {1}", Rules[i], Vectors[j]);
}
}
//---------- ---------- ---------- ----------
Console.ReadKey();
}
}
}
| Sposób 1 | Method 1 |
|---|---|
| Co będzie, jeśli spróbujemy zbadać milion reguł dla miliona wektorów, sprawdzając prawdziwość każdej reguły dla każdego badanego wektora? | What happens if you try to verify truth of one million rules for one million vectors, checking accuracy of each rule for each vector? |
| Sposób 2 | Method 2 |
| Co będzie, jeśli spróbujemy zbadać tylko dwie reguły (nazwijmy je hipotezami), sprwadzając prawdziwość każdej reguły tylko dla dwóch wektorów (nazwijmy te wektory reprezentatywnymi próbkami)? | What happens if you try to verify truth of only two rules (let's name them hypothesis) for only two vectors (let's name them representative samples)? |
| Odpowiedź: | Answer: |
| Sprawdzanie prawdziwości reguł w przypadku 2 potrwa na pewno krócej, niż w przypadku 1. | Checking truth of case 2 will last certainly shorter than of case 1. |
| Dlaczego? | Why? |
| W przypadku Sposobu 1 mamy | Using Method 1 we get |
1.000.000 x 1.000.000 = 1.000.000.000.000 |
1.000.000 x 1.000.000 = 1.000.000.000.000 |
| testów do wykonania. | tests to do. |
| W przypadku Sposobu 2 mamy tylko | Using Method 2 We only get |
2 x 2 = 4 |
2 x 2 = 4 |
| testy do wykonania. | tests to do. |
| Odpowiedz sobie sam, co będzie, jeśli jeden test trwa jedną sekundę lub procesor musi przeznaczyć na ten test jeden proces, lub jeden test zajmuje jeden zespół badaczy przez tydzień? | Ask yourself, what would happen if single test takes one second or processor must allocate for this test one process, or one test involves single team of researchers for a week? |
| Dobra praktyka | Good practice |
| W związku z powyższym, jest stosowane następujące podejście w problemach poszukiwania reguł w danych: | Accordingly, following approach is practiced in problems of searching rules in data: |
| Zwykle wybiera się wstępnie pewną reprezentatywną próbkę danych. | Typically, we pre-select representative sample of data. |
| Tu właśnie przydaje się kontekst i cel, a z pewnością także trochę doświadczenia. | This is where context and purpose are useful and certainly some experience. |
| Próbka nie jest już tak liczna, jak cały zbiór danych. | The sample is not as large as entire data set. |
| Jeżeli zbieranie danych potraktujemy jako eksperyment, to takie eksperymenty się planuje, tak jak tworzy się plan testów programu. | If we treat collecting data as an experiment then we plan such experiments, like we create a tests plan for computer program. |
| Nie da się przebadać wszystkich pacjentów na świecie i wybiera się małą, ale reprezentatywną grupę, w której jest szansa na zadziałanie leku. | It is impossible to examine all patients in the world and scientists select a small but representative group, in which there is a chance for success of tested medicine. |
| To czego nie da rady zrobić zwykły program w C#, przy tej samej złożoności algorytmu SQL zrobi wielokrotnie szybciej. | What we cannot do using regular C# program, SQL can do many times faster with the same algorithm complexity. |
| Wiązania: | Bindings: |
LEFT OUTER JOIN |
LEFT OUTER JOIN |
| tj. każdy z każdym, | means each to each, |
| są czymś zupełnie naturalnym w SQL, ponieważ SQL operuje na zbiorach (za wyjątkiem wymuszonych iteracji, użytych przeze mnie), a nie na pojedynczych wierszach tabel. | are perfectly natural in SQL, because SQL operates on sets (except forced iterations used by me), and not on single rows of tables. |
| Znacznie lepiej jest z góry założyć jeden lub tylko kilka modeli szukanych reguł, niż szukać reguł wszelkich. | It's much better to put up one or only a few models of searched rules rather than seek any rules. |
| Rzeczywiste dane mają zawsze swój kontekst i od tego kontekstu należy uzależnić cel poszukiwań, czyli model reguły lub modele reguł. | Actual data is always context data and within this context man should make purpose of research, means model of rules or models of ones. |
A4. Gromadzenie danych / Collecting data
| A.4 Gromadzenie danych | A.4 Collecting data |
|---|---|
| Dane gromadzi się w hurtowniach danych, jeżeli organizację lub zespół badawczy na to stać. | Data is stored in data warehouses when organization or research group can afford it. |
| Hurtownia danych to już wielka skala. | Data warehouse is already a big scale. |
| Bez dedykowanych specjalistycznych algorytmów raczej trudno sobie z nią poradzić. | No dedicated specialized algorithms is rather difficult to deal with it. |
| Dzisiaj (rok 2013) żyjemy w epoce tzw. chmur i tzw. zbiorów Big Data, co oznacza gromadzenie i analizę danych na jeszcze większą skalę niż w hurtowniach danych. | Today (year 2013), we live in age of so-called clouds and so-called Big Data sets, what means collecting and analyzing data on an even larger scale than in data warehouses. |
| Jeżeli w organizacji jeden oddział osiąga lepsze rezultaty od innego, to znalezienie ukrytej reguły w zgromadzonych danych może pozwolić na zastosowanie działań podejmowanych przez lepszy oddział w innych słabszych oddziałach. | If one branch of organization achieves better results than another, finding hidden rule in collected data may allow actions taken by superior branch in other weaker ones. |
| Innym słowy można znaleźć odpowiedź na pytanie: dlaczego jedni wypadają lepiej od innych? | In other words, you can find answer to question why some branches perform better than others? |
| Podobnie jest z lekami i wynikami badań pacjentów, którym zaaplikowano różne leki i terapie. | The same is true of medicines and patient test results, which were applied various medicines and therapies. |
| Wniosek z wyników badań może się przyczynić do znalezienia lepszej terapii i lepszego zestawu leków. | Application of research results can help finding better treatments and better set of medicines. |
| Wektory, o jakich mówię są nazywane: wektorami, przypadkami, instancjami. | Vectors about which I say are called: vectors, cases, instances. |
| Nazwa jest bez znaczenia – wszystko to można przedstawić za pomocą wektorów. | Name does not matter - all that can be represented by vectors. |
| Elementy wektorów to atrybuty. | Elements of vectors are attributes. |
A.5 Teraźniejszość i przyszłość / Present and future
| A.5 Teraźniejszość i przyszłość | A.5 Present and future |
|---|---|
| Moje rozwiązania możesz mieć w dzisiejszych czasach na swoim biurku w domu nie mając dostępu do internetu. | You can have my solutions at your desk at home without access to Internet these days. |
| Czy potrafisz sobie wyobrazić, że następne pokolenia będą mogły mieć współczesne chmury i zbiory Big Data w swoich domach na swoich biurkach także nie mając dostępu do internetu? | Can you imagine that next generations will be able to have nowadays clouds and Big Data sets in their homes at their desks not having access to Internet? |
B. Literatura uzupełniająca / Reference materials
Po polsku / Polish
Eksploracja danych, Wikipedia
Hurtownia danych, Wikipedia
Big data, Wikipedia
Metody i Style Zarządzania, LOSMARCELOS, 4programmers.net
Po angielsku / English
Data Mining, Wikipedia
Big Data, IBM
Po polsku i po angielsku / Polish and English
Regułowy System ekspercki / Rule-driven expert system, Artur Protasewicz, 4programmers.net
B.1 Warte polecenia / Recommendable
Po polsku i po angielsku / Polish and English
Angielski dla programistów / English for programmers, krokodyl, 4programmers.net
C. Program do ekstrakcji reguł z danych C# / Program extracting rules from data C#
C.1 Sprawdzenie poprawności algorytmu szukania reguł / Rules search algorithm verification
| C.1 Sprawdzenie poprawności algorytmu szukania reguł | C.1 Rules search algorithm verification |
|---|---|
| Głównym problemem, z jakim się spotkałem było: jak sprawdzić, że podawane przez mój program reguły są prawidłowe? | Main problem I met was: how to check that rules being found by my program were correct? |
| Nie dysponowałem rzeczywistymi zbiorami danych. | I did not have data sets taken from life. |
| Rozwiązaniem było wygenerowanie zbioru danych losowych przez generator liczb losowych, | Solution was to generate set of random data by random number generator, |
| jednak sam generator musiał generować dane zawierające w sobie znaną regułę. | but such generator itself had to generate data containing well-known rule. |
| Jeżeli użyje się takiego generatora i stworzy określony zbiór liczb, to program powinien znaleźć regułę (zależność między liczbami), według której generator tworzył ten zbiór. | Using such generator and creating specific set of numbers program should find rules (relationships between numbers) according to rule which generator put to such collection. |
| Zaprojektowałem 3 generatory liczb losowych. | I designed 3 random number generators. |
| Pierwszy tworzy dane losowo i wszystkie reguły są jednakowo prawdopodobne. | First one creates data randomly and all rules are equally likely. |
| Drugi używa tylko jednej reguły dla wszystkich danych. Pewna losowość występuje, ale reguła tej losowości jest jedna. | Second one uses only single rule for all data. Some randomness occurs but rule of randomness is one. |
| Trzeci generator używa 4-ech reguł i powstają 4 podzbiory jednego zbioru danych średnio zawierające 25% wszystkich danych zbioru. | Third generator uses four rules and creates four subsets of data set containing average of 25% of total data set. |
| Jednak jest to tylko średnia, bo proporcje ilościowe między podzbiorami tylko w sumie tworzą 100%, a mogą być np. 50%, 20%, 20%, 10%. | However this is only average, because quantitative proportions between subsets only in total make up 100% and may be for example 50%, 20%, 20%, 10%. |
| W tej sytuacji należy się spodziewać od 1-nej do 4-ech reguł dla całego zbioru. | In this situation you should expect from 1 to 4 rules for whole set. |
| Mój program znajduje reguły zawarte w zbiorze danych zgodnie z regułami tworzenia zbioru przez generatory liczb losowych. | My program finds rules given to set of random numbers by their creation process. |
| Świadczy to o poprawności algorytmu | This proves correctness of algorithm. |
C.2 Kryteria jakościowe / Quality criteria
| C.2 Kryteria jakościowe | C.2 Quality criteria |
|---|---|
| Program wylicza procent danych, dla których określona reguła ma zastosowanie. | Program calculates percentage of data for which specific rule applies. |
| Jednak w moim programie jedna reguła zawiera dwie klasy. | But in my program one rule contains 2 classes. |
| Postać przykładowej reguły: | Sample rule form: |
jeżeli [(A > B) oraz (C > D) oraz (E > F) oraz (G > H)]to [(X < Y) lub (Y < 0)] |
if [(A > B) and (C > D) and (E > F) and (G > H)]then [(X < Y) or (Y < 0)] |
| Możemy to zapisać: | We can write: |
jeżeli [zbiór faktów] to [(klasa 1) lub (klasa 2)] |
if [set of facts] then [(class 1) or (class 2)] |
| Może się zdarzyć, że taka reguła wskazuje zarówno na klasę 1 jak i na klasę 2. | It may happen such rule refers both class 1 and class 2. |
| Co wtedy zrobić? | What to do then? |
| Musimy wybrać jedną z dwóch klas – tę, która opisuje więcej danych w przypadku danej reguły. | We have to choose one of two classes - one that describes more data for given rule. |
C.2.1 Kryterium minimum / Minimum criterion
| C.2.1 Kryterium minimum | C.2.1 Minimum criterion |
|---|---|
| Po pierwsze, musimy wprowadzić kryterium określające minimalną procentową ilość danych, które reprezentuje każda klasa jednej reguły, aby w ogóle brać ją pod uwagę. | First, we introduce criterion relating to minimum percentage of data, that represents each class of one rule, to take it into account in general. |
C.2.2 Kryterium odstępu klas / Classes interval criterion
| C.2.2 Kryterium odstępu klas | C.2.2 Classes interval criterion |
|---|---|
| Jeżeli reguła odnosi się do więcej, niż jednej klasy, wprowadzamy drugie kryterium, określające minimalny odstęp między klasami, | If rule applies to more than one class, we introduce second criterion specifying minimum distance between classes, |
| który pozwala zdecydować, czy klasy są znacząco odróżnialne. | which allows you to decide whether classes are enough exceptional. |
| Jeżeli nie są, to nie można zdecydować, którą klasę reprezentuje reguła | If not you can not decide which class the rule represents |
| i nie można w ogóle zaakceptować tej reguły, bo jest niejednoznaczna. | and it is impossible to accept this rule because it is ambiguous. |
| Np. w przypadku 5-ciu klas najszybciej da się wyznaczyć średnią udziałów procentowych | For example having 5 classes very quick method is to determine average of percentages |
| i wybrać najbardziej oddaloną od średniej klasę, jako najbardziej jednoznaczną. | and choose most distanted from average one as the most unambiguous. |
C.2.3 Kryterium oceny zbioru reguł / Found rules set evaluation criterion
| C.2.3 Kryterium oceny zbioru reguł | C.2.3 Found rules set evaluation criterion |
|---|---|
| Pierwsze dwa kryteria pozwalają na utworzenie zbioru reguł zawartych w danych. | First two criteria allow creation of set of rules contained in data. |
| Jednak, kiedy zbiór danych ma np. 100 wektorów: | However, when data set contains eg. 100 vectors: |
[ X Y A B C D E F G H ] |
[ X Y A B C D E F G H ] |
| i wykryjemy 50 reguł o podobnej formie, o dobrej jakości ze względu na dwa pierwsze kryteria, | and we detect 50 rules having similar form and good quality due to first two criteria, |
| to tak naprawdę nie będziemy w stanie przeanalizować takiego zbioru reguł i na niewiele on nam się zda. | we really are not able to analyze such set of rules and we have nothing. |
| Trzeba wprowadzić jeszcze jedno kryterium do oceny jakości zbioru reguł. | You need to make one more criterion to assess quality of set of rules. |
| Przyjąłem normę następująco: | I assumed norm as follows: |
Q = [(ilośćWektorów)–(ilośćReguł)] / [ilośćWektorów] |
Q = [(NumberOfVectors)–(NumberOfRules)] / [NumberOfVectors] |
| To kryterium można ustalać w zależności od różnorodności form reguł i naszych oczekiwań, | This criterion can be determined basing on diversity of rules and our expectations, |
| a także planów dotyczących dalszego przetwarzania. | as well as plans for further processing. |
| Moim założeniem jest, że dalej już człowiek będzie decydował o postępowaniu ze znalezionymi regułami | My assumption is, that further just man will decide on proceeding with the found rules |
| i wskazane jest, aby nie było ich zbyt wiele i o to chodzi w moim kryterium. | and it is advisable that there were not too many rules as result and that's the point of my criterion. |
| Eksperymenty potwierdzają, że przy przyjętym algorytmie takie kryterium nie pokazuje dużych odchyleń na zbiorach generowanych z zadaną regułą, | Experiments confirm, that algorithm adopted such criterion does not show large deviations on sets generated from the given rule, |
| a jest wrażliwe i mocno się odchyla dla zbiorów generowanych w pełni losowo (nazwijmy je "bez żadnej reguły"; ale czy istnieje jakikolwiek zbiór pozbawiony reguł). | and it is sensitive and strongly deviates for sets generated completely randomly (let's name them "non-rule" sets; but does any "non-rule" set exist?). |
D. Program / Program
D.1 Widok okna programu / Program window
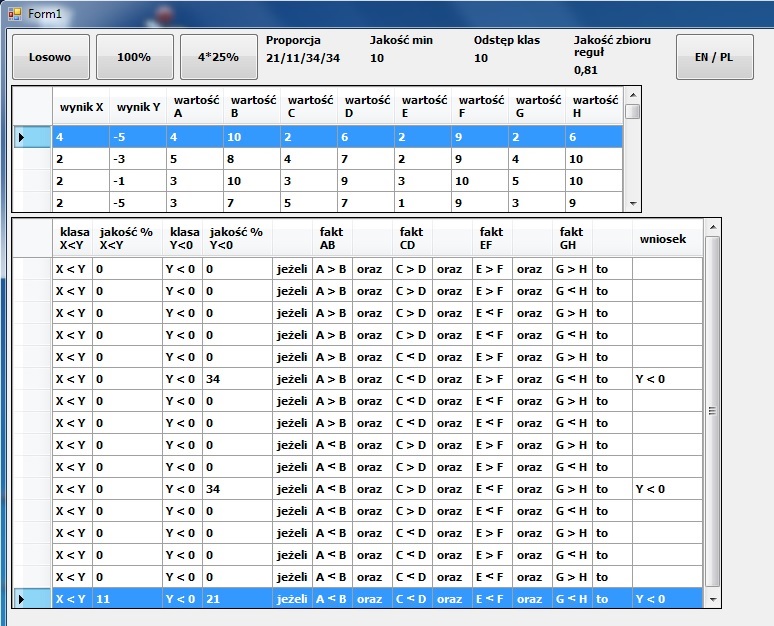
| D.1 Widok okna programu | D.1 Program window |
|---|---|
| Okno zawiera 3 przyciski do generowania zbiorów danych przy pomocy 3-ech różnych generatorów liczb losowych. | Window contains 3 buttons to generate data sets using 3 different random number generators. |
| Po kliknięciu przycisku oprócz wygenerowania zbioru danych, znajdowane są reguły go opisujące. | After clicking a button data set is generated and rules that describe it are being found. |
| Etykieta "Proporcja" pokazuje ilościowy stosunek danych generowanych trzecim generatorem, | Label "Ratio" shows quantitative ratio of data generated by third generator, |
który używa 4-ech reguł (przycisk "4*25%"). |
that uses 4 rules (button "4*25%"). |
| Dla pozostałych dwóch generatorów nie ma zastosowania. | For other two generators it does not apply. |
| Pokazana jest jakość minimalna (patrz C.2.1), | Minimum quality is displayed (see C.2.1), |
| która jest parametrem wpisywanym w kodzie programu, | which is parameter in program code, |
| podobnie jak odstęp klas (patrz C.2.2). | like classes interval (see C.2.2). |
| Jakość zbioru reguł jest wyznaczana po jego znalezieniu według podanego wzoru (patrz C.2.3). | Quality of rules set is calculated when rules are found using given formula (see C.2.3). |
| W podświetlonym na niebiesko wierszu u dołu tabeli Reguły, | As highlighted in blue line at bottom of table Rules, |
| w kolumnie | in column |
"Jakość% X<Y" jest wartość 11, |
"Quality% X<Y" there's value 11, |
| która oznacza, że 11% badanych wektorów spełnia podświetloną regułę. | which means that 11% of vectors correspond to highlighted rule. |
| W kolumnie | In column |
"Jakość% Y<0" jest liczba 21, |
"Quality% Y<0" there is value 21, |
| która oznacza, że 21% badanych wektorów spełnia podświetloną regułę. | which means, that 21% of vectors correspond to highlighted rule. |
| Obie liczby są większe od 10, | Both values are greater than 10, |
| czyli od jakości minimalnej. | which is minimum quality. |
| Aby podjąć decyzję o wybraniu jednej z dwóch klas: | To decide to select one of two classes: |
"X<Y" lub "Y<0" |
"X<Y" or "Y<0" |
| po pierwsze wybieramy 21, czyli wartość większą, | first you select greater value 21, |
| ale dodatkowo odejmujemy | but you additionally subtract |
21–11 = 10, |
21-11 = 10, |
| co oznacza, że klasy są wystarczająco odróżnialne w ramach zadanego minimalnego odstępu klas 10 | what means that classes are enough exceptional within specified minimum classes interval 10 |
| i można w ogóle wybrać jedną z nich. | and you can even select one of them. |
| Krócej: | Shorter: |
| Jeżeli | If |
max(11,21) = 21 |
max(11,21) = 21 |
| oraz | and |
21>=10 |
21>=10 |
| oraz | and |
21–11 >= 10 |
21–11 >= 10 |
| to | then |
"wniosek" = (Y<0) |
"conclusion" = (Y<0) |
| Różnice w jakości zbioru reguł będą najlepiej widoczne przy generowaniu reguł dla zbioru całkowicie losowego (przycisk "Losowo"). | Differences in rules set quality will be most visible when generating rules set completely random (button "Random"). |
| Można łatwo zaobserwować, | It is easy to notice, |
| że mamy do czynienia tylko z jedną formą reguły (jedną klasą reguł), tj.: | that there's only one form of rule (one class of rules), ie.: |
jeżeli [(A o B) oraz (C o D) oraz (E o F) oraz (G o H)]to [(X<Y) lub (Y<0)] |
if [(A o B) and (C o D) and (E o F) and (G o H)]then [(X<Y) or (Y<0)] |
| gdzie `o = {większe | mniejsze}` |
| Logicznego ORAZ używałem zawsze, | I've been always using logical AND, |
| ale dodatkowo wprowadziłem również w to miejsce logiczne LUB. | but in addition I also introduced in its place logical OR. |
| Lepiej sprawdza się ORAZ, | AND is better, |
| ponieważ wprawdzie daje mniej reguł, | because however it gives less rules, |
| ale za to bardziej precyzyjnych. | but they are more precise. |
| W kodzie programu słowo "operator" zastąpiłem słowem "relacja". | In program code I replaced word "operator" with word "relation". |
| Z punktu widzenia programisty operatory relacji takie jak | From developer's perspective relational operators such as |
"<",">","=" |
"<",">","=" |
| należą do szerszego zbioru operatorów, | belong to wider set of operators, |
| do których także zaliczają się operatory arytmetyczne | which also include arithmetic operators |
"+","-","*","/", |
"+","-","*","/", |
| ale w takim ujęciu każda relacja jest operatorem, | but in such approach every relation is operator, |
| jednak nie każdy operator jest relacją. | however not every operator is relation. |
| Być może matematyk zgłosiłby błąd, | Maybe mathematician would report mistake, |
| ale kontekstem są pojęcia z programowania. | but context is concepts of programming. |
D.2 Kod programu / Program code
| D.2 Kod programu | D.2 Program code |
|---|---|
| Program powstał w MS C# 2010 Express. | My program's been created in MS C# 2010 Express. |
| Jest tu zawarty pełny kod, także tworzący kontrolki na formie. | I included full code here, also creating controls on form. |
| Można pobrać projekt z załącznika do tej strony, klikając link w następnym punkcie D.2.1 poniżej. | You can download my project enclosed as attachment to this site, by clicking link in following point D.2.1 below. |
| Wszystkie funkcje są zawarte w klasie Form1, która jednak jest rozbita na moduły. | All functions are inside class Form1, which however is divided into modules. |
| Moim celem było pokazanie algorytmu, a nie pokazywanie programowania obiektowego. | My purpose was to show algorithm, and not to show object programming. |
/* Moduł 02_rnd_init.cs */
/* Module 02_rnd_init.cs */
using System;
using System.Windows.Forms;
namespace DataMiner
{
public partial class Form1 : Form
{
void Form1_Load(object sender, EventArgs e)
{
// Form1_Load inicjuje generator liczb losowych
// Form1_Load intitiates random number generator
NativeRandomGenerator = new Random();
}
}
}
```csharp /* Moduł 03_base_rand.cs */ /* Module 03_base_rand.cs */
using System.Windows.Forms;
namespace DataMiner
{
public partial class Form1 : Form
{
int Less()
{
// Less() generuje liczby losowe ze zbioru {1 2 3 4 5}
// Są one zawsze mniejsze od generowanych przez funkcję Greater() tj. {6 7 8 9 10}
// Less() generates random numbers of set {1 2 3 4 5}
// They are always less than those generated by Greater() means {6 7 8 9 10}
return NativeRandomGenerator.Next(AbsoluteRandomValueRange / 2) + 1;
}
int Greater()
{
// Greater() generuje liczby losowe ze zbioru {6 7 8 9 10}
// Są one zawsze większe od generowanych przez funkcję Less() tj. {1 2 3 4 5}
// Greater() generates random numbers of set {6 7 8 9 10}
// They are always greater than those generated by Less() means {1 2 3 4 5}
return (NativeRandomGenerator.Next(AbsoluteRandomValueRange / 2) + 1) + (AbsoluteRandomValueRange / 2);
}
int Rnd()
{
// Rnd() generuje liczby ze zbioru {1 2 3 4 5 6 7 8 9 10}
// Rnd() generates random numbers of set {1 2 3 4 5 6 7 8 9 10}
return NativeRandomGenerator.Next(AbsoluteRandomValueRange) + 1;
}
int SignedRnd()
{
// SignedRnd() generuje liczby losowe ze zbioru {-10 ... -1, 1 ... 10}; Uwaga: bez zera
// SignedRnd() generates random numbers of set {-10 ... -1, 1 ... 10}; Note: no zero included
return ((NativeRandomGenerator.Next(2) == 0) ? -1 : 1) * (NativeRandomGenerator.Next(AbsoluteRandomValueRange) + 1);
}
bool TrueOrFalse()
{
// TrueOrFalse() generuje wartości bool ze zbioru {true, false}
// TrueOrFalse() generates boolean values of set {true, false}
return (NativeRandomGenerator.Next(2) == 0);
}
}
}
<hr />
```csharp
/* Moduł 04_vector_rand_1.cs */
/* Module 04_vector_rand_1.cs */
using System.Windows.Forms;
namespace DataMiner
{
public partial class Form1 : Form
{
void FactAB(out int parA, out int parB, bool parAGreaterB)
{
// FactAB(...) generuje pary (A B) (C D) (E F) (G H) zależnie od parametru parAGreaterB
// FactAB(...) generates pairs (A B) (C D) (E F) (G H) dependent on parameter parAGreaterB
if (parAGreaterB)
{
// Para o postaci "A > B"
// Pair of form "A > B"
parA = Greater();
parB = Less();
}
else
{
// Para o postaci "A < B"
// Pair of form "A < B"
parA = Less();
parB = Greater();
}
}
void FactXY(out int X, out int Y, bool parYLessZero)
{
// FactXY(...) generuje pary liczb losowych (X Y) zależnie od parametru parYLessZero
// FactXY(...) generates pairs of random numebrs (X Y) dependent on parameter parYLessZero
if (parYLessZero)
{
// Klasa "Y < 0"
// Class "Y < 0"
X = +Less();
Y = -Less();
}
else
{
// Klasa "X < Y"
// Class "X < Y"
X = Less();
Y = Greater();
}
}
/*
Symetrie:
Jeżeli dobrze się przyjrzeć generowanym liczbom
znajdziemy tu dla poszczególnych wartości k = {0 1 2 3} następujące symetrie:
klasa "Y < 0" :: klasa "X < Y"
Less, Greater :: Greater, Less
FactAB(A, B), FactAB(C, D) :: FactAB(E, F), FactAB(G, H)
FactAB(A, B), FactAB(C, D), E, F, G, H :: A, B, C, D FactAB(E, F), FactAB(G, H)
FactAB(A, B), C, D Fact(E, F), G, H :: A, B, FactAB(C, D), E, F, FactAB(G, H)
Symetrie pozwalają na to, że generator liczb losowych spełni przy wielu uruchomieniach
wszystkie reguły i nie wyróżni żadnej z nich
*/
/*
Symmetries:
If you look at generated numbers
you can find there for each k = {0 1 2 3} following symmetries:
class "Y < 0" :: class "X < Y"
Less, Greater :: Greater, Less
FactAB(A, B), FactAB(C, D) :: FactAB(E, F), FactAB(G, H)
FactAB(A, B), FactAB(C, D), E, F, G, H :: A, B, C, D FactAB(E, F), FactAB(G, H)
FactAB(A, B), C, D Fact(E, F), G, H :: A, B, FactAB(C, D), E, F, FactAB(G, H)
Symmetries allow that random number generator fills with many starts,
all rules and do not make any of them exceptional
*/
void Symmetry(int k)
{
FactXY(out X, out Y, yLessZeroClass[k]);
switch (k)
{
case 0:
FactAB(out A, out B, GreaterAB);
FactAB(out C, out D, GreaterCD);
E = Less();
F = Greater();
G = Less();
H = Greater();
break;
case 1:
A = Less();
B = Greater();
C = Less();
D = Greater();
FactAB(out E, out F, GreaterEF);
FactAB(out G, out H, GreaterGH);
break;
case 2:
A = Greater();
B = Less();
FactAB(out C, out D, GreaterCD);
E = Greater();
F = Less();
FactAB(out G, out H, GreaterGH);
break;
case 3:
FactAB(out A, out B, GreaterAB);
C = Greater();
D = Less();
FactAB(out E, out F, GreaterEF);
G = Greater();
H = Less();
break;
default:
break;
}
}
}
}
```csharp /* Moduł 05_vector_rand_2.cs */ /* Module 05_vector_rand_2.cs */
using System.Windows.Forms;
namespace DataMiner
{
public partial class Form1 : Form
{
void FillRandom()
{
// Pierwszy generator liczb losowych
// Ilość reguł istniejących w zbiorze danych jest nieprzewidywalna
// 1st random number generator
// Number of rules existing in data set is unpredictable
for (int i = 0; i < VectorCountMaxArrSize; i++)
{
X = SignedRnd();
Y = SignedRnd();
A = Rnd();
B = Rnd();
C = Rnd();
D = Rnd();
E = Rnd();
F = Rnd();
G = Rnd();
H = Rnd();
ArrData[resultXIdx, i] = X;
ArrData[resultYIdx, i] = Y;
ArrData[attrAIdx, i] = A;
ArrData[attrBIdx, i] = B;
ArrData[attrCIdx, i] = C;
ArrData[attrDIdx, i] = D;
ArrData[attrEIdx, i] = E;
ArrData[attrFIdx, i] = F;
ArrData[attrGIdx, i] = G;
ArrData[attrHIdx, i] = H;
}
gridData.RowCount = VectorCountMaxArrSize;
}
void Fill100PerCent()
{
// Drugi generator liczb losowych
// Wystąpi tylko jedna reguła opisująca cały zbiór danych
// 2nd random number generator
// There will be only one rule that describes entire data set
yLessZeroClass[0] = TrueOrFalse();
GreaterAB = TrueOrFalse();
GreaterCD = TrueOrFalse();
GreaterEF = TrueOrFalse();
GreaterGH = TrueOrFalse();
for (int ds = 0; ds < VectorCountMaxArrSize; ds++)
{
FactXY(out X, out Y, yLessZeroClass[0]);
FactAB(out A, out B, GreaterAB);
FactAB(out C, out D, GreaterCD);
FactAB(out E, out F, GreaterEF);
FactAB(out G, out H, GreaterGH);
ArrData[resultXIdx, ds] = X;
ArrData[resultYIdx, ds] = Y;
ArrData[attrAIdx, ds] = A;
ArrData[attrBIdx, ds] = B;
ArrData[attrCIdx, ds] = C;
ArrData[attrDIdx, ds] = D;
ArrData[attrEIdx, ds] = E;
ArrData[attrFIdx, ds] = F;
ArrData[attrGIdx, ds] = G;
ArrData[attrHIdx, ds] = H;
}
gridData.RowCount = VectorCountMaxArrSize;
}
void Fill25PerCent()
{
// Trzeci generator liczb losowych (wykorzystujący symetrię)
// Wystąpi od 1 do 4 reguł
// W przypadku 4-ech reguł średnio jedna będzie opisywała 25% zbioru danych
// 3rd random number generator (using symmetry)
// There will be from 1 to 4 rules
// In case of four-quadrant rules mean one would describe the 25% of data set
int[] countDiv = new int[4];
countDiv[0] = 0;
countDiv[1] = 0;
countDiv[2] = 0;
countDiv[3] = 0;
yLessZeroClass[0] = TrueOrFalse();
yLessZeroClass[1] = TrueOrFalse();
yLessZeroClass[2] = TrueOrFalse();
yLessZeroClass[3] = TrueOrFalse();
GreaterAB = TrueOrFalse();
GreaterCD = TrueOrFalse();
GreaterEF = TrueOrFalse();
GreaterGH = TrueOrFalse();
// Tablica Div zawiera początki i końce przedziałów generowanych liczb
// Ponieważ mają być 4 przedziały, będzie 5 ich wartości brzegowych tj. 0, 25, 50, 75 i 100
// Array Div contains beginnings and ends of ranges of numbers generated
// As there will be four ranges, there will be 5 boundary values, ie. 0, 25, 50, 75 and 100
int[] Div = new int[5];
Div[0] = 0;
// Przedział [1...25]
// Range [1...25]
Div[1] = (NativeRandomGenerator.Next(VectorCountMaxArrSize / 4) + 1) + 0 * (VectorCountMaxArrSize / 4);
// Przedział [26...50]
// Range [26...50]
Div[2] = (NativeRandomGenerator.Next(VectorCountMaxArrSize / 4) + 1) + 1 * (VectorCountMaxArrSize / 4);
// Przedział [51...75]
// Range [51...75]
Div[3] = (NativeRandomGenerator.Next(VectorCountMaxArrSize / 4) + 1) + 2 * (VectorCountMaxArrSize / 4);
// Przedział [76...100], co wynika z dalej występujących pętli for
// Range [76...100], due to further occurring for loops
Div[4] = VectorCountMaxArrSize;
for (int j = 0; j < 4; j++)
{
for (int i = Div[j]; i < Div[j + 1]; i++)
{
Symmetry(j);
ArrData[resultXIdx, i] = X;
ArrData[resultYIdx, i] = Y;
ArrData[attrAIdx, i] = A;
ArrData[attrBIdx, i] = B;
ArrData[attrCIdx, i] = C;
ArrData[attrDIdx, i] = D;
ArrData[attrEIdx, i] = E;
ArrData[attrFIdx, i] = F;
ArrData[attrGIdx, i] = G;
ArrData[attrHIdx, i] = H;
countDiv[j]++; // Obliczanie ilości wektorów w jednym przedziale
// Calculation of vector count in one range
}
}
gridData.RowCount = VectorCountMaxArrSize;
// Tu: Wyświetlenie ilości danych dla każdej z 4-ech reguł na formie
// Here: Displaying ratio of amount of data for each of four-quadrant rules at form
lblDiv.Text = countDiv[0].ToString() + "/" +
countDiv[1].ToString() + "/" +
countDiv[2].ToString() + "/" +
countDiv[3].ToString();
}
}
}
<hr />
```csharp
/* Moduł 06_fill_rules.cs */
/* Module 06_fill_rules.cs */
using System.Windows.Forms;
namespace DataMiner
{
public partial class Form1 : Form
{
void FillRules(AndOrOperatorEnum rel)
{
int count = 0;
/*
Kolejne zagnieżdżone pętle for 0...1 tworzą permutację,
której odpowiednikiem są kolejne liczby od 0 do 15 w postaci binarnej
0000
0001
0010
0011
0100 itd.
(...)
1111 na końcu
Liczbie 0 przypisujemy ">", a liczbie 1 "<" i otrzymujemy 16 reguł tej samej formy (klasy)
W szczególności przy użyciu równocześnie AND i OR, jednak w różnych regułach
powstają 32 reguły (o jeden bit więcej w zapisie binarnym)
*/
/*
Successive nested for loops 0...1 create permutation,
which is equivalent to numbers from 0 to 15 in binary
0000
0001
0010
0011
0100 etc.
(...)
1111 at end
We assign ">" to 0, and "<" to 1, and we get 16 rules of the same form (class)
In particular, by using both AND and OR, but in different rules
32 rules are formed (one bit more in binary notation)
*/
for (int ab = 0; ab < 2; ab++)
{
string AB = (ab == 0) ? "A > B" : "A < B";
for (int cd = 0; cd < 2; cd++)
{
string CD = (cd == 0) ? "C > D" : "C < D";
for (int ef = 0; ef < 2; ef++)
{
string EF = (ef == 0) ? "E > F" : "E < F";
for (int gh = 0; gh < 2; gh++)
{
string GH = (gh == 0) ? "G > H" : "G < H";
if (rel != AndOrOperatorEnum.rAndOr)
{
ArrRules[xLessYIdx, count] = "X < Y";
ArrRules[yLessZeroIdx, count] = "Y < 0";
ArrRules[ifIdx, count] = CellValueIf[Language];
ArrRules[factABIdx, count] = AB;
ArrRules[factCDIdx, count] = CD;
ArrRules[factEFIdx, count] = EF;
ArrRules[factGHIdx, count] = GH;
if (rel == AndOrOperatorEnum.rAnd)
{
ArrRules[operator0Idx, count] = CellValueAnd[Language];
ArrRules[operator1Idx, count] = CellValueAnd[Language];
ArrRules[operator2Idx, count] = CellValueAnd[Language];
}
else if (rel == AndOrOperatorEnum.rOr)
{
ArrRules[operator0Idx, count] = CellValueOr[Language];
ArrRules[operator1Idx, count] = CellValueOr[Language];
ArrRules[operator2Idx, count] = CellValueOr[Language];
}
ArrRules[thenIdx, count] = CellValueThen[Language];
count++;
}
else if (rel == AndOrOperatorEnum.rAndOr)
{
for (int iRel = 0; iRel < 2; iRel++)
{
ArrRules[xLessYIdx, count] = "X < Y";
ArrRules[yLessZeroIdx, count] = "Y < 0";
ArrRules[ifIdx, count] = CellValueIf[Language];
ArrRules[factABIdx, count] = AB;
ArrRules[factCDIdx, count] = CD;
ArrRules[factEFIdx, count] = EF;
ArrRules[factGHIdx, count] = GH;
// Reguła może zawierać tylko operatory "Oraz" lub tylko operatory "Lub"
// Inne reguły nie są generowane
// Rule can contain only operators "And" or only operators "Or"
// Other rules are not generated
if (iRel == 0)
{
ArrRules[operator0Idx, count] = CellValueAnd[Language];
ArrRules[operator1Idx, count] = CellValueAnd[Language];
ArrRules[operator2Idx, count] = CellValueAnd[Language];
}
else if (iRel == 1)
{
ArrRules[operator0Idx, count] = CellValueOr[Language];
ArrRules[operator1Idx, count] = CellValueOr[Language];
ArrRules[operator2Idx, count] = CellValueOr[Language];
}
ArrRules[thenIdx, count] = CellValueThen[Language];
count++;
}
}
}
}
}
}
if (rel != AndOrOperatorEnum.rAndOr)
gridRules.RowCount = RuleCount; // 16, specyficzne dla tego projektu
// 16, this project specific
else if (rel == AndOrOperatorEnum.rAndOr)
gridRules.RowCount = RuleCount; // 32, specyficzne dla tego projektu
// 32, this project specific
}
}
}
```csharp /* Moduł 07_search_rules.cs */ /* Module 07_search_rules.cs */
using System.Windows.Forms;
namespace DataMiner
{
public partial class Form1 : Form
{
void CountStat()
{
/*
Procedura obliczająca ile procent zbioru danych opisują poszczególne reguły
Na końcu wyliczone wartości są wpisywane do tablicy ArrRules w kolumnach "Jakość % A > B" oraz "Jakość % X < Y".
Celowo podałem postaci tekstowe faktów np. "A > B" i klas np. "X < Y",
choć ten element nie jest tu konieczny, ale lepiej obrazuje o co chodzi
*/
/*
Procedure calculating percentage of data set described by particular rules
At end of calculation values are written to array ArrRules into columns "Quality % A > B" and "Quality % X < Y".
Intentionally I gave textual facts, such as "A > B" and such as "X < Y"
although this part is not necessary here, but better reflects what's going on
*/
for (int ruleRow = 0; ruleRow < gridRules.RowCount; ruleRow++)
{
int countXLessY = 0;
int countYLessZero = 0;
for (int classXY = 0; classXY < 2; classXY++)
{
for (int dataRow = 0; dataRow < gridData.RowCount; dataRow++)
{
string sClassXY;
switch (classXY)
{
case 0:
sClassXY = ArrRules[xLessYIdx, ruleRow];
break;
case 1:
sClassXY = ArrRules[yLessZeroIdx, ruleRow];
break;
default:
sClassXY = "";
break;
}
string sFactAB = ArrRules[factABIdx, ruleRow];
string sFactCD = ArrRules[factCDIdx, ruleRow];
string sFactEF = ArrRules[factEFIdx, ruleRow];
string sFactGH = ArrRules[factGHIdx, ruleRow];
string sRelation = ArrRules[operator0Idx, ruleRow];
bool vFactAB;
bool vFactCD;
bool vFactEF;
bool vFactGH;
if (sFactAB == "A > B")
vFactAB = (ArrData[attrAIdx, dataRow] > ArrData[attrBIdx, dataRow]);
else
vFactAB = (ArrData[attrAIdx, dataRow] < ArrData[attrBIdx, dataRow]);
if (sFactCD == "C > D")
vFactCD = (ArrData[attrCIdx, dataRow] > ArrData[attrDIdx, dataRow]);
else
vFactCD = (ArrData[attrCIdx, dataRow] < ArrData[attrDIdx, dataRow]);
if (sFactEF == "E > F")
vFactEF = (ArrData[attrEIdx, dataRow] > ArrData[attrFIdx, dataRow]);
else
vFactEF = (ArrData[attrEIdx, dataRow] < ArrData[attrFIdx, dataRow]);
if (sFactGH == "G > H")
vFactGH = (ArrData[attrGIdx, dataRow] > ArrData[attrHIdx, dataRow]);
else
vFactGH = (ArrData[attrGIdx, dataRow] < ArrData[attrHIdx, dataRow]);
bool vFacts;
if (sRelation == CellValueAnd[Language])
vFacts = vFactAB && vFactCD && vFactEF && vFactGH;
else if (sRelation == CellValueOr[Language])
vFacts = vFactAB || vFactCD || vFactEF || vFactGH;
else
vFacts = false;
bool vClassXY;
if (sClassXY == "X < Y")
{
vClassXY = (ArrData[resultXIdx, dataRow] < ArrData[resultYIdx, dataRow]);
if (vClassXY && vFacts) countXLessY++;
}
else if (sClassXY == "Y < 0")
{
vClassXY = (ArrData[resultYIdx, dataRow] < 0);
if (vClassXY && vFacts) countYLessZero++;
}
}
}
ArrRules[statXLessYIdx, ruleRow] = (100 * (double)countXLessY / 100).ToString("F00");
ArrRules[statYLessZeroIdx, ruleRow] = (100 * (double)countYLessZero / 100).ToString("F00");
}
}
void FillConclusion(int qualityClassInterval, int qualityMinimum)
{
/*
Funkcja analizuje obliczone przez CountStat() wartości procentowe,
rozpatruje kryteria jakościowe (patrz artykuł: punkt C.2)
i decyduje o dodaniu reguły do wynikowego zbioru reguł
*/
/*
Function analyzes calculated by CountStat() percentages,
considers quality criteria (see article point C.2)
and decides whether to add rule to resulting set of rules
*/
for (int ruleRow = 0; ruleRow < gridRules.RowCount; ruleRow++)
{
int valueXlessY = int.Parse(ArrRules[statXLessYIdx, ruleRow]);
int valueYlessZero = int.Parse(ArrRules[statYLessZeroIdx, ruleRow]);
bool XLessY = false;
bool YLessZero = false;
int classifyCount = 0;
// qualityClassInterval - odstęp klas
// qualityMininimum - minimum wymagane do uznania reguły za reprezentatywną
// qualityClassInterval - classes interval
// qualityMininimum - minimum necessary to accept rule as representative
if (valueXlessY - valueYlessZero >= qualityClassInterval && valueXlessY >= qualityMinimum)
{
XLessY = true;
classifyCount++;
}
if (valueYlessZero - valueXlessY >= qualityClassInterval && valueYlessZero >= qualityMinimum)
{
YLessZero = true;
classifyCount++;
}
// classifyCount == 1 powoduje, że niejednoznaczna klasyfikacja nie zachodzi
// Umieściłem ten warunek dla porządku, bowiem jest rozstrzygnięty już powyżej
// classifyCount == 1 means that there is no ambiguous classification
// I put this condition for order, because it is already resolved above
if (classifyCount == 1 && XLessY)
ArrRules[conclusionIdx, ruleRow] = ArrRules[xLessYIdx, ruleRow];
else if (classifyCount == 1 && YLessZero)
ArrRules[conclusionIdx, ruleRow]
= ArrRules[yLessZeroIdx, ruleRow];
else
ArrRules[conclusionIdx, ruleRow] = "";
}
}
}
}
<hr />
```csharp
/* Moduł 08_rules_quality.cs */
/* Module 08_rules_quality.cs */
using System.Windows.Forms;
namespace DataMiner
{
public partial class Form1 : Form
{
void FillRuleSetQuality()
{
// Funkcja oceniająca jakość uzyskanego zbioru reguł (patrz atykuł: punkt C.2.3)
// Function evaluating quality of final set of rules (see article: point C.2.3)
int ruleCtr = 0;
int allVectorCount = 0;
for (int i = 0; i < gridRules.RowCount; i++)
{
if (ArrRules[conclusionIdx, i] != "")
ruleCtr++;
allVectorCount++;
}
double quality = (double)(allVectorCount - ruleCtr) / allVectorCount;
if (ruleCtr > 0)
lblSetOfRulesQ.Text = quality.ToString("F02");
else
lblSetOfRulesQ.Text = "";
}
}
}
```csharp /* Moduł 09_btn_click.cs */ /* Module 09_btn_click.cs */
using System;
using System.Windows.Forms;
namespace DataMiner
{
public partial class Form1 : Form
{
/*
We wszystkich poniższych zdarzeniach Click występuje identyczna kolejność wywołań funkcji:
1. Wypełnienie zbioru danych (wektorów) przy pomocy generatora liczb losowych
2. Wypełnienie zbioru reguł bez określania wartości procentowych
3. Obliczenie wartości procentowych
4. Decyzja o dodaniu poszczególnych reguł do zbioru wynikowego
5. Wyświetlenie danych z tablic w gridach
6. Ocena jakości zbioru reguł
*/
/*
In all events click below there is identical sequence of function calls:
1. Filling data set (vectors set) using Random number generator
2. Filling rules set except percentages
3. Calculating percentages
4. Decision about adding particular rules to resulting set
5. Displaying array data in grids
6. Evaluation of rules set quality
*/
void bFillRandom_Click(object sender, EventArgs e)
{
// Kliknięcie przycisku "Losowo"
// Clicking button "Random"
lblDiv.Text = "";
FillRandom();
FillRules(AndOrOperatorEnum.rAndOr);
CountStat();
int qualityDistance = 10;
int qualityMin = 10;
FillConclusion(qualityDistance, qualityMin);
lblQMin.Text = qualityMin.ToString();
lblQDelta.Text = qualityDistance.ToString();
Display(ArrData, gridData);
Display(ArrRules, gridRules);
FillRuleSetQuality();
}
void b100PerCent_Click(object sender, EventArgs e)
{
// Kliknięcie przycisku "100 %"
// Clicking button "100 %"
lblDiv.Text = "";
Fill100PerCent();
FillRules(AndOrOperatorEnum.rAnd);
CountStat();
int qualityDistance = 10;
int qualityMin = 10;
FillConclusion(qualityDistance, qualityMin);
lblQMin.Text = qualityMin.ToString();
lblQDelta.Text = qualityDistance.ToString();
Display(ArrData, gridData);
Display(ArrRules, gridRules);
FillRuleSetQuality();
}
void b25PerCent_Click(object sender, EventArgs e)
{
// Kliknięcie przycisku "4 * 25%"
// Clicking button "4 * 25%"
Fill25PerCent();
FillRules(AndOrOperatorEnum.rAnd);
CountStat();
int qualityDistance = 10;
int qualityMin = 10;
FillConclusion(qualityDistance, qualityMin);
lblQMin.Text = qualityMin.ToString();
lblQDelta.Text = qualityDistance.ToString();
Display(ArrData, gridData);
Display(ArrRules, gridRules);
FillRuleSetQuality();
}
void Display(int[,] Arr, DataGridView grid)
{
// Aby obliczenia były szybsze są wykonywane na tablicach,
// a dopiero potem z tablic przepisuje się informacje do gridów funkcjami Display
// Parametrem jest tablica wartości typu int
// To make calculation faster we perfom it using arrays
// and then values from arrays are put to grids using Display
// Array of int as parameter here
for (int col = 0; col < grid.ColumnCount; col++)
for (int row = 0; row < grid.RowCount; row++)
grid[col, row].Value = Arr[col, row];
}
void Display(string[,] Arr, DataGridView grid)
{
// Aby obliczenia były szybsze są wykonywane na tablicach,
// a dopiero potem z tablic przepisuje się informacje do gridów funkcjami Display
// Parametrem jest tablica wartości typu string
// To make calculation faster we perfom it using arrays
// and then values from arrays are put to grids using Display
// Array of string as parameter here
for (int col = 0; col < grid.ColumnCount; col++)
for (int row = 0; row < grid.RowCount; row++)
grid[col, row].Value = Arr[col, row];
}
}
}
#### D.2.1 Pobierz projekt / Download project
Kliknij tutaj / Click here [DataMiner.zip](//4programmers.net/Download/138719/368)
## E. Ekstrakcja reguł przy użyciu dynamicznego SQL / Extraction of rules using dynamic SQL
E. Ekstrakcja reguł przy użyciu dynamicznego SQL | E. Extraction of rules using dynamic SQL
---------------- | ----------------
Przypomnę szukaną postać reguły: | Let's remind searched form of rule:
`jeżeli [(A > B) oraz (C > D) oraz (E > F) oraz (G > H)]`<br /> `to [(X < Y) lub (Y < 0)]` | `if [(A > B) and (C > D) and (E > F) and (G > H)]</code><br /><code>then [(X < Y) or (Y < 0)]`
To jest: | This is:
`jeżeli [zbiór faktów] to [(klasa 1) lub (klasa 2)]` | `if [set of facts] then [(class 1) or (class 2)]`
Przy czym również przypominam, że szukamy równocześnie wielu reguł, w których operatory relacji to zestawy czwórek: | Also remember that we are looking for many rules at the same time and relational operators in these rules are sets of fours:
`(o AB) | (o CD) | (o EF) | (o GH) := o: { "<", ">" }` | `(o AB) | (o CD) | (o EF) | (o GH) := o: { "<", ">" }`
Zrobiłem test dla miliona (1 000 000) wektorów: | I did test for one million (1 000 000) vectors:
`[ X Y A B C D E F G H ]` | `[ X Y A B C D E F G H ]`
W tym celu posłużyłem się MS SQL Server'em Express 2008. | For this purpose I used MS SQL Server Express 2008.
Ponieważ pracuję lokalnie, wystarczające było uruchomienie zbioru kwerend bezpośrednio na serwerze z poziomu Management Studio. | Because I work locally it was sufficient set of queries were run directly on server from within Management Studio.
Ale docelowo zbiór kwerend pokazany poniżej w punkcie E.4 powinien stanowić procedurę składową serwera. | But collection of queries shown below in point E.4 should be a Stored Procedure as target.
Mechanizm jest taki, że to na serwerze, a nie w C# jest uruchamiana w SQL procedura analogiczna do `FillRules(Relation.rAnd)` | The point of mechanism is that SQL procedure analogous to `FillRules(Relation.rAnd)` is run on server and not by C#
i tworzy ona unię (UNION) zapytań (SELECT), a te wyliczają udział danych, dla których reguła jest spełniona we wszystkich danych. | and it creates UNION of SELECT queries and those calculate per cent of all data for which particular rule fit.
O ile kryterium minimum z punktu C.2.1 zostało zachowane, to zmieniło się kryterium odstępu klas C.2.2. | While minimum criterion C.2.1 hasn't changed, interval classes criterion C.2.2 changed.
W tym przykładzie brane są pod uwagę tylko sytuacje dla których zachodzi: | In this example situations taken into account are only ones where there is:
`(klasa 1) xor (klasa 2) = true` | `(class 1) xor (class 2) = true`
co jest równoważne | what is equivalent for
`(q odstęp) = 100` | `(q interval) = 100`
co oznacza, że może zachodzić tylko: | what means that there can only take place:
`X < Y` | `X < Y`
lub tylko: | either only:
`Y < 0` | `Y < 0`
Jeżeli te warunki są spełnione równocześnie, to taka reguła nie jest brana pod uwagę. | If these conditions are met at the same time then such rule is not taken into account.
Nie zmienia to specjalnie wynikowego zbioru reguł opisujących dane. | This does not change much resulting set of rules describing data.
To jest po prostu ostrzejsze kryterium dające mniej reguł, ale za to maksymalnie precyzyjnych. | This is just much more selective criterion resulting less amount of rules but they are maximum precise ones.
### E.1 Utworzenie bazy danych SQL Server oraz tabeli / Creating SQL Server database and table
E.1 Utworzenie bazy danych SQL Server oraz tabeli | E.1 Creating SQL Server database and table
---------------- | ----------------
Na serwerze utworzyłem bazę danych, a w niej jedną tabelę Vectors, w której znalazło się milion wektorów. | I created a database on server and a table Vectors in which there were one million vectors.
```sql
USE master
CREATE DATABASE DataMiner
GO
USE DataMiner
CREATE TABLE Vectors(
VectorId int NOT NULL,
X int NULL,
Y int NULL,
A int NULL,
B int NULL,
C int NULL,
D int NULL,
E int NULL,
F int NULL,
G int NULL,
H int NULL,
CONSTRAINT [PK_Vectors] PRIMARY KEY (VectorId ASC)
)
ON [PRIMARY]
E.2 Wypełnienie tabeli danymi / Filling data table
| E.2 Wypełnienie tabeli danymi | E.2 Filling data table |
|---|---|
| Tabela została wypełniona danymi przy pomocy generatora działającego w oparciu o 4 reguły o średnim udziale procentowym 25% danych. | The table had been filled with data using random generator based on 4 rules of average percentage 25%. |
| Wystarczyło przerobić procedurę | It was good enough to replace procedure |
Fill25PerCent() |
Fill25PerCent() |
| na analogiczną, jednak wpisującą dane na serwer. | by analogous one, however inserting data to server. |
| Pracowałem na komputerze z procesorem i5, 8GB RAM i dyskiem SSD. | I was working on computer with i5 processor, 8GB RAM and SSD disk. |
| Jeżeli masz słabszy komputer, zacznij nie od miliona, a od np. 100 wektorów, jak to było dotychczas. | If your computer is not so efficient, start not from one million, but eg. 100 vectors, like it was till now. |
| W tym celu zmień linijkę: | In such a case change line: |
while (VectorId <= 1000000) |
while (VectorId <= 1000000) |
| zmieniając liczbę milion na sto. | changing number million to hundred. |
| Potem możesz stopniowo zwiększać tę ilość. | Then, you can successively increase this value. |
| Generowanie tego zbioru (milion) na moim komputerze trwa 50 sekund. | Generating of the set (million) on my computer takes 50 seconds. |
| Nie chciałbym, abyś czekał przez godzinę. | This is not my intention, you had to wait for an hour. |
/* Moduł 10 sql_fill.cs */
/* Module 10 sql_fill.cs */
using System;
using System.Windows.Forms;
using System.Data.SqlClient;
namespace DataMiner
{
public partial class Form1 : Form
{
void sqlFill25PerCent()
{
// Procedura analogiczna do Fill25PerCent() jednak wpisująca dane (milion wektorów) do bazy danych SQL Server Express
// Nazwa bazy danych to DataMiner
// Procedure similar to Fill25PerCent(), however, entering data (1 million vectors) into SQL Server Express database
// Database name is DataMiner
int[] countDiv = new int[4];
countDiv[0] = 0;
countDiv[1] = 0;
countDiv[2] = 0;
countDiv[3] = 0;
yLessZeroClass[0] = TrueOrFalse();
yLessZeroClass[1] = TrueOrFalse();
yLessZeroClass[2] = TrueOrFalse();
yLessZeroClass[3] = TrueOrFalse();
GreaterAB = TrueOrFalse();
GreaterCD = TrueOrFalse();
GreaterEF = TrueOrFalse();
GreaterGH = TrueOrFalse();
int[] div = new int[5];
div[0] = 0;
div[1] = (NativeRandomGenerator.Next(100 / 4) + 1) + 0 * (100 / 4); // 1...25
div[2] = (NativeRandomGenerator.Next(100 / 4) + 1) + 1 * (100 / 4); // 26...50
div[3] = (NativeRandomGenerator.Next(100 / 4) + 1) + 2 * (100 / 4); // 51...75
div[4] = 100;
string ConnStr = "Data Source=.\\SQLEXPRESS;"
+ "Integrated Security=True;"
+ "Initial Catalog=DataMiner;";
try
{
SqlConnection Conn = new SqlConnection(ConnStr);
Conn.Open();
SqlCommand CmdDelete = new SqlCommand("DELETE FROM Vectors");
CmdDelete.Connection = Conn;
CmdDelete.ExecuteNonQuery();
int VectorId = 1;
while (VectorId <= 1000000)
{
for (int j = 0; j < 4; j++)
{
for (int i = div[j]; i < div[j + 1]; i++)
{
Symmetry(j);
SqlCommand CmdInsert = new SqlCommand("INSERT Vectors (VectorId, X,Y,A,B,C,D,E,F,G,H) "
+ "VALUES (@VectorId,@X,@Y,@A,@B,@C,@D,@E,@F,@G,@H)");
CmdInsert.Parameters.AddWithValue("@VectorId",
VectorId);
CmdInsert.Parameters.AddWithValue("@X", X);
CmdInsert.Parameters.AddWithValue("@Y", Y);
CmdInsert.Parameters.AddWithValue("@A", A);
CmdInsert.Parameters.AddWithValue("@B", B);
CmdInsert.Parameters.AddWithValue("@C", C);
CmdInsert.Parameters.AddWithValue("@D", D);
CmdInsert.Parameters.AddWithValue("@E", E);
CmdInsert.Parameters.AddWithValue("@F", F);
CmdInsert.Parameters.AddWithValue("@G", G);
CmdInsert.Parameters.AddWithValue("@H", H);
CmdInsert.Connection = Conn;
CmdInsert.ExecuteNonQuery();
VectorId++;
}
}
}
Conn.Close();
}
catch (Exception ex)
{
MessageBox.Show(ex.ToString());
}
}
}
}
E.2.1 Sprawdzenie otrzymanego zbioru / Checking out result set
| E.2.1 Sprawdzenie otrzymanego zbioru | E.2.1 Checking out result set |
|---|---|
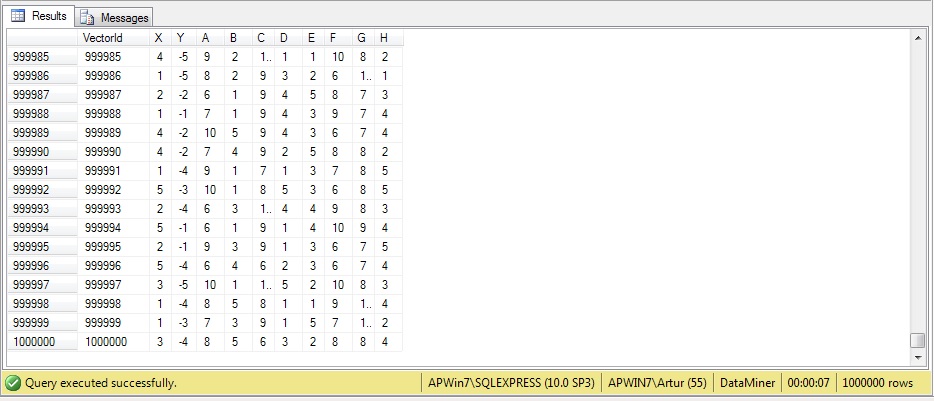
| Warto sprawdzić, co się wygenerowało, gdyż dalszy algorytm nie jest zabezpieczony przed wystąpieniem pustego zbioru. | It's worth checking out, what has been generated, because the algorithm is not empty set-safe. |
Odczytywanie zbioru przez SQL Server trwa 7 sekund, co widać poniżej na żółtym pasku (zapis 00:00:07) |
Reading the set by SQL Server takes 7 seconds, what you can see at yellow bar below (shown 00:00:07) |
SELECT * FROM Vectors |
SELECT * FROM Vectors |
E.3 Przykładowy kod SQL dla jednej reguły, tworzony dynamicznie / Sample SQL code created dynamically
| E.3 Przykładowy kod SQL dla jednej reguły, który ma być tworzony dynamicznie | E.3 Sample SQL code created dynamically |
|---|---|
| Na początek pokażę na przykładzie sprawdzenia jednej reguły zapisanej w SQL, co będzie generował serwer, a takich reguł powstanie 16. | At the beginning I will show on single SQL rule checking, what will be generated by server, and there will be 16 such a rules. |
| To nie jest pomyłka, że w jednej regule tyle razy występuje kwerenda | It's not a mistake, that in single rule there's so many queries |
SELECT |
SELECT |
| i jeden raz | and one |
UNION |
UNION |
| Zaraz to wyjaśnię. | Let's explain it. |
| Zacznijmy od najbardziej zagnieżdżonych fragmentów: | Let's start from most nested parts: |
Pierwszy fragment wybiera wektory jednej klasy X < Y spełniające określony warunek dla A, B, C, D, E, F, G, H. |
First part selects vectors of one class X < Y meeting given condition for A, B, C, D, E, F, G. |
SELECT * FROM Vectors |
SELECT * FROM Vectors |
WHERE X < Y AND NOT Y < 0 |
WHERE X < Y AND NOT Y < 0 |
AND A < B AND C < D AND E < F AND G < H |
AND A < B AND C < D AND E < F AND G < H |
Drugi fragment robi to samo dla klasy Y < 0 |
Second part does the same for class Y < 0 |
SELECT * FROM Vectors |
SELECT * FROM Vectors |
WHERE Y < 0 AND NOT X < Y |
WHERE Y < 0 AND NOT X < Y |
AND A < B AND C < D AND E < F AND G < H |
AND A < B AND C < D AND E < F AND G < H |
| Reguła zawierająca dwie klasy została rozbita na dwie. | The rule containing two classes has been divided into two ones. |
Mamy spełnić kryterium jakościowe (klasa 1) xor (klasa 2) |
We have to match quality criterion (class 1) xor (class 2) |
| W SQL nie ma funkcji XOR. | There's no XOR function in SQL. |
| Funkcja ta zapisuje się jako: | Function writes as: |
[(klasa 1) oraz nie (klasa 2)] oraz [(klasa 2) oraz nie (klasa 1)] |
[(class 1) and not (class 2)] and [(class 2) and not (class 1)] |
| Muszą to być zbiory rozłączne. | These must be disjoint. |
| Wejdźmy o poziom zagnieżdżenia wyżej. | Let's go level of nesting upper. |
| Zapis postaci: | Formula of form: |
SELECT ... FROM (SELECT ... FROM) T |
SELECT ... FROM (SELECT ... FROM) T |
| w nawiasie zawiera jedną kwerendę tworzącą wirtualną tabelę T, | contains in parentheses one query creating virtual table T, |
| a dopiero z tej tabeli dane wybiera zewnętrzna kwerenda | from which data are selected by less nested query |
SELECT |
SELECT |
| poza nawiasem. | out of parenthesis. |
| Taka sytuacja występuje dwukrotnie, a kwerendy zewnętrzne poza nawiasem dodatkowo łączy unia (UNION). | This situation appears twice, and out of parenthesis queries are joined by union (UNION). |
| W wyniku powstaje jedna tabela złożona z dwóch (tu powstaną 2 wiersze z agregacjami). | As a result you get one table consisting of two (here you get two rows with aggregations). |
| Tworząc unię musimy zachować identyczny zestaw kolumn (także co do typu danych) pochodzących z kwerend wchodzących w skład unii. | Creating union you must use identical collection of columns (also considering data type) which come from queries building union. |
| Docelowo chciałem, aby SQL wyświetlił mi reguły w zapisie tekstowym i do tego jest kolumna | Destinatelly I wanted, so that SQL displayed textual rules, and this is role of column |
[RULE] |
[RULE] |
| oraz procent danych, który pasuje do reguły w kolumnie | and percentage of data matching the rule in column |
[STAT %] |
[STAT%] |
| Ten procent wylicza zapis: | This percentage is calculated by: |
100 * ROUND(CAST(COUNT(*) AS REAL) / (SELECT COUNT(*) FROM Vectors) |
100 * ROUND(CAST(COUNT(*) AS REAL) / (SELECT COUNT(*) FROM Vectors) |
| Najlepiej będzie jeśli wyjaśnię ten zapis pisząc to samo w C#. | The best is to show it writting C# code. |
//podzbiór wektorów spełniających warunek przynależności do klasy |
// subset of vectors meeting condition of belonging to the class |
// np. 25 wektorów |
// eg. 25 vectors |
int Count_1 = VectorSubSet; |
int Count_1 = VectorSubSet; |
// ilość wszystkich wektorów np. 1000 wektorów |
//amount of all vectors eg. 1000 ones |
int Count_2 = AllVectorCount; |
int Count_2 = AllVectorCount; |
// procent udziału podzbioru w całym zbiorze |
// integer percentage of subset in whole set, |
// wyrażony liczbą całkowitą tu: 100 * 25 / 1000 |
//here: 100 * 25 / 1000 |
int Stat = 100 * (int)((double)Count_1 / Count_2); |
int Stat = 100 * (int)((double)Count_1 / Count_2); |
| Zwróć uwagę, że Count_1 odnosi się do tabeli wirtualnej T. | Pay attention, Count_1 refers to the virtual table T. |
| Stąd cały ten zabieg, żeby stworzyć dwie agregacje i je przez siebie podzielić. | That's what all this is for – to create two aggregations and divide them one by another. |
USE DataMiner
SELECT
[RULE] = 'IF A < B and C < D and E < F and G < H THEN X < Y'
,[STAT %] = 100 * ROUND(CAST(COUNT(*) AS REAL) / (SELECT COUNT(*) FROM Vectors), 2)
FROM
(
SELECT * FROM Vectors
WHERE X < Y AND NOT Y < 0 AND A < B AND C < D AND E < F AND G < H
) T
UNION
SELECT
[RULE] = 'IF A < B and C < D and E < F and G < H THEN Y < 0'
,[STAT %] = 100 * ROUND(CAST(COUNT(*) AS REAL) / (SELECT COUNT(*) FROM Vectors), 2)
FROM
(
SELECT * FROM Vectors
WHERE Y < 0 AND NOT X < Y AND A < B AND C < D AND E < F AND G < H
) T
E.4 Dynamiczne tworzenie zbioru kwerend i znajdowanie reguł / Dynamic creating set of queries and finding rules
| E.4 Dynamiczne tworzenie zbioru kwerend i znajdowanie reguł | E.4 Dynamic creating set of queries and finding rules |
|---|---|
| Teraz będzie chodziło o to, żeby zapisywać SQL w zmiennej tekstowej, | Now, it's about putting SQL in text variable, |
ostatecznie @QUERY |
finally @QUERY |
| a potem wykonać to, co jest w niej zapisane poleceniem: | and then running one by using statement: |
EXEC(@QUERY) |
EXEC(@QUERY) |
Dodałem jeszcze warunek zawierający jakościowe kryterium minimum q_min = 10 |
I added quality minimum criterion q_min = 10 |
| Reszta to składanie kolejnych unii o postaci omówionej w poprzednim punkcie, | The rest is joining successive unions about which told in previous point, |
| które też zostaną połączone uniami. | which also be joined by unions. |
Będą się różnić jedynie zestawami (permutacją) operatorów { <, > }. |
They differ collections (permutation) of operators only { <, > }. |
UWAGA: Ilość znaków, która może się znaleźć w @QUERY |
NOTE: Amount of characters, appearing in @QUERY |
| jest ograniczona i trzeba zwracać uwagę na to, | is limited and you must pay attention |
| czy końcowy fragment nie jest obcięty. | the final characters are not trimed. |
| Wówczas SQL zasygnalizuje trudny do przewidzenia i zrozumienia błąd. | In such a case SQL will signal unpredictable error difficult to understand. |
| W związku z tym staraj się pisać ciasno – bez zbędnych spacji | Because of that you shall put characters closely – without not needed blanks, |
i najpierw zamiast EXEC wykonuj PRINT |
and before running EXEC run PRINT |
| Jak widać nie zawsze podejście z dynamicznym tworzeniem SQL będzie możliwe. | As you can see not always dynamic SQL approach is possible. |
| Ale warto czasem spróbować, żeby cała operacja wykonała się po stronie serwera. | But sometimes it's worth to try, so that whole operation was done on server-side. |
| To ją znacznie przyspiesza. | It makes one much faster. |
PAMIĘTAJ: Najpierw przetestuj na PRINT |
REMEMBER: First, try PRINT |
i w ogóle nie używaj tej metody, kiedy nie możesz przewidzieć długości tekstu @QUERY |
and never use this method, when you can't predict length of text of @QUERY |
USE DataMiner
--Zmienna decydująca o dopisywaniu słowa UNION
--Variable deciding about inserting word UNION
DECLARE @i INT
--Zmienna iterująca operatory "<", ">" dla A, B
--Variable iterating operators "<", ">" for A, B
DECLARE @iAB INT
--Zmienna iterująca operatory "<", ">" dla C, D
--Variable iterating operators "<", ">" for C, D
DECLARE @iCD INT
--Zmienna iterująca operatory "<", ">" dla E, F
--Variable iterating operators "<", ">" for E, F
DECLARE @iEF INT
--Zmienna iterująca operatory "<", ">" dla G, H
--Variable iterating operators "<", ">" for G, H
DECLARE @iGH INT
--String z operatorem dla A, B
--String inserting operator for A, B
DECLARE @sAB VARCHAR(10)
--String z operatorem dla C, D
--String inserting operator for C, D
DECLARE @sCD VARCHAR(10)
--String z operatorem dla E, F
--String inserting operator for E, F
DECLARE @sEF VARCHAR(10)
--String z operatorem dla G, H
-- String inserting operator for G, H
DECLARE @sGH VARCHAR(10)
--Zmienna iterująca klasy "X < Y", "Y < 0"
--Variable iterating classes "X < Y", "Y < 0"
DECLARE @iCLASS INT
--String z jedną z klas "X < Y" lub "Y < 0"
--String with a single class "X < Y" either "Y < 0"
DECLARE @sCLASS VARCHAR(100)
--String na klauzulę WHERE
--String for clause WHERE
DECLARE @WHERE VARCHAR(100)
--String na słowo UNION
--String for word UNION
DECLARE @UNION VARCHAR(100)
--Pierwsza część kwerendy SELECT
--First part of query SELECT
DECLARE @SELECT1 VARCHAR(100)
--Ostatnia część kwerendy SELECT
--Last part of query SELECT
DECLARE @SELECT2 VARCHAR(100)
--String z listą warunków np. A<B AND C<D AND E<F AND G<H
--String with list of conditions eg. A<B AND C<D AND E<F AND G<H
DECLARE @AT VARCHAR(100)
--Ilość wektorów w tabeli Vectors
--Number of vectors in table Vectors
DECLARE @N VARCHAR(30)
--Wniosek "X < Y" lub "Y < 0"
--Conclusion "X < Y" either "Y < 0"
DECLARE @CONCLUSION VARCHAR(10)
--String z wygenerowanym dynamicznie zapytaniem SQL
--String with dynamically generated SQL query
DECLARE @QUERY VARCHAR(8000)
--Kryterium jakościowe QMIN
--Quality criterion QMIN
DECLARE @QMIN VARCHAR(10)
--Generowanie zbioru kwerend
--Generating set of queries
SET @QMIN = '10'
SET @i = 1
SET @QUERY = ''
SET @N = '(SELECT COUNT(*) from Vectors)'
SET @SELECT1 = 'SELECT [STAT %] = 100 * ROUND(CAST(COUNT(*) as REAL) /' + @N + ',2) '
SET @SELECT2 = 'FROM (SELECT * FROM Vectors'
SET @iCLASS = 0;
WHILE (@iCLASS < 2) BEGIN
SET @iAB = 0;
WHILE (@iAB < 2) BEGIN
SET @iCD = 0;
WHILE (@iCD < 2)BEGIN
SET @iEF = 0;
WHILE (@iEF < 2)BEGIN
SET @iGH = 0;
WHILE (@iGH < 2) BEGIN
IF @iAB = 0 SET @sAB = '>' ELSE SET @sAB = '<'
IF @iCD = 0 SET @sCD = '>' ELSE SET @sCD = '<'
IF @iEF = 0 SET @sEF = '>' ELSE SET @sEF = '<'
IF @iGH = 0 SET @sGH = '>' ELSE SET @sGH = '<'
IF @iCLASS = 0 SET @sCLASS = 'X<Y AND NOT Y<0 ' ELSE SET @sCLASS = 'Y<0 AND NOT X<Y ';
IF @iCLASS = 0 SET @CONCLUSION = ' THEN X<Y'' ' ELSE SET @CONCLUSION = ' THEN Y<0'' '
SET @AT = 'A' + @sAB + 'B AND C' + @sCD + 'D AND E' + @sEF + 'F AND G' + @sGH + 'H'
SET @WHERE = ' WHERE ' + @sCLASS + 'AND ' + @AT + ')V '
IF @i < 32 SET @UNION = 'UNION ' ELSE SET @UNION = ''
--2 linie kodu poniżej są przydatne przy testowaniu generowanych zapytań
--2 lines of code below are useful while testing generated queries
--SET @QUERY = @SELECT1 + ',[RULE]=' + '''IF ' + @AT + @CONCLUSION + @SELECT2 + @WHERE + @UNION
--PRINT (@QUERY)
--Następną linię kodu w czasie testów należy wziąć w komentarz i użyć dwóch poprzednich
--Next line of code shall be commented during tests, and you should use two lines of code above
SET @QUERY = @QUERY + @SELECT1 + ',[RULE]=' + '''IF ' + @AT + @CONCLUSION + @SELECT2 + @WHERE + @UNION
SET @i = @i + 1;
SET @iGH = @iGH + 1;
END
SET @iEF = @iEF + 1;
END
SET @iCD = @iCD + 1;
END
SET @iAB = @iAB + 1;
END
SET @iCLASS = @iCLASS + 1;
END
--Wykonanie zbioru kwerend i znalezienie reguł
--Set of queries execution finding rules
EXEC ('SELECT * FROM (' + @QUERY + ')V WHERE [STAT %] > ' + @QMIN)
E.5 Rezultat użytego algorytmu SQL / Result of SQL algorithm use
| E.5 Rezultat użytego algorytmu SQL | E.5 Result of SQL algorithm use |
|---|---|
| I o poniższy efekt chodziło. | And that's it below. |
| Wykonało się to na milionie wektorów (dziesięciu milionach liczb int) w czasie 6-ciu sekund na komputerze z procesorem i5, 8GB RAM, dysk SSD. | It has been performed on one million vectors (ten million integer numbers) during 6 seconds on a computer with i5 processor, 8GB RAM, SSD disk. |
| Szukaliśmy podzbioru z 16 reguł do wnioskowania o 2-óch klasach (faktycznie zrobiliśmy to na 32-óch regułach po jednej klasie). | There was a subset of 16 rules searched to describe 2 classes (in fact, it has been done on 32 rules - each of one class). |
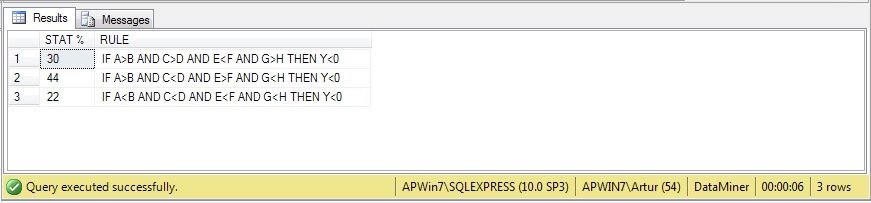
F. Uzupełnienie kodu C# - tworzenie kontrolek na formie / Complement code C# - creating controls on form
/* Moduł 01_Form1.cs */
/* Module 01_Form1.cs */
using System;
using System.Drawing;
using System.Windows.Forms;
using System.Data.SqlClient;
namespace DataMiner
{
public partial class Form1 : Form
{
// Standardowy generator liczb losowych C# / Windows
// Standrd C# / Windows random number generator
Random NativeRandomGenerator;
// Typy poszukiwanych reguł
// Types of searched rules
enum AndOrOperatorEnum
{
rAnd, // Dla reguł będących iloczynem logicznym faktów postaci A > B
// For rules being logical conjunction of facts of form A > B
rOr, // Dla reguł będących alternatywą logiczną faktów postaci A > B
// For rules being logical alterntive of facts of form A > B
rAndOr // Dla zbiorów reguł zawierających oba powyższe rodzaje reguł
// For sets of rules containing both forms of rules above
}
int AbsoluteRandomValueRange = 10; // Zakres wartości danych {-10 do 10}
// Range of values {from -10 to 10}
int X, Y, A, B, C, D, E, F, G, H; // Zmienne tworzące wektor
// Variables forming vector
bool[] yLessZeroClass = new bool[4]; // Klasa "Y < 0", jeżeli true; Klasa "X < Y", jeżeli false
// If true then class "Y < 0"; else class "X < Y"
// Warunki "A > B", "C > D", "E > F", "G > H", jeżeli przyjmują wartości true, a jeżeli false, to "A < B" itd.
// If true then conditions "A > B", "C > D", "E > F", "G > H", else "A < B" etc.
bool GreaterAB, GreaterCD, GreaterEF, GreaterGH;
static int VectorElementCount = 10; // Liczba elementów wektora
// Number of values forming vector
static int VectorCountMaxArrSize = 100; // Maksymalna dozwolona liczba wektorów
// Max. allowed number of vectors
// Tablica zawierająca dane, w których szukamy reguł
// Array containing data in which we search for rules
int[,] ArrData = new int[VectorElementCount, VectorCountMaxArrSize];
static int OperatorCount = 2; // Liczba operatorów (Oraz, Lub)
// Number of operators (And, Or)
static int RuleCount = 16; // Liczba reguł
// Number of rules
// Liczba elementów reguły
// Number of elements of rule
static int RuleElementCount = 14;
// Tablica zawierająca reguły
// Array containing rules
string[,] ArrRules = new string[RuleElementCount, RuleCount * OperatorCount];
// Indeksy kolumn w tabelach i gridach
// Column indexes in arrays and grids
int resultXIdx = 0;
int resultYIdx = 1;
int attrAIdx = 2;
int attrBIdx = 3;
int attrCIdx = 4;
int attrDIdx = 5;
int attrEIdx = 6;
int attrFIdx = 7;
int attrGIdx = 8;
int attrHIdx = 9;
int xLessYIdx = 0;
int statXLessYIdx = 1;
int yLessZeroIdx = 2;
int statYLessZeroIdx = 3;
int ifIdx = 4;
int factABIdx = 5;
int operator0Idx = 6;
int factCDIdx = 7;
int operator1Idx = 8;
int factEFIdx = 9;
int operator2Idx = 10;
int factGHIdx = 11;
int thenIdx = 12;
int conclusionIdx = 13;
// Liczba wierszy gridów
// Number of grid rows
int visibleDataRowCount = 4;
int visibleRulesRowCount = 16;
// Kontrolki wizualne
// Visual controls
Button bFillRandom;
Button b100PerCent;
Button b25PerCent;
Button bLanguage;
Label lblDivText;
Label lblDiv;
Label lblQMinText;
Label lblQMin;
Label lblQDeltaText;
Label lblQDelta;
Label lblSetOfRulesQText1;
Label lblSetOfRulesQText2;
Label lblSetOfRulesQ;
DataGridView gridData;
DataGridView gridRules;
public Form1()
{
// Ta część kodu nie jest opisana - tworzenie kontrolek na formie
// Code without comments - creating controls on form
InitializeComponent();
this.Font = new Font("Tahoma", 8, FontStyle.Bold);
bFillRandom = new Button();
bFillRandom.Size = new Size(80, 48);
bFillRandom.Location = new Point(4, 4);
bFillRandom.Text = BtnTextRandom[Language];
this.Controls.Add(bFillRandom);
b100PerCent = new Button();
b100PerCent.Size = new Size(80, 48);
b100PerCent.Location = new Point(bFillRandom.Left + bFillRandom.Width + 4, 4);
b100PerCent.Text = "100%";
this.Controls.Add(b100PerCent);
b25PerCent = new Button();
b25PerCent.Size = new Size(80, 48);
b25PerCent.Location = new Point(b100PerCent.Left + b100PerCent.Width + 4, 4);
b25PerCent.Text = "4*25%";
this.Controls.Add(b25PerCent);
lblDivText = new Label();
lblDivText.Location = new Point(b25PerCent.Left + b25PerCent.Width + 4, 4);
lblDivText.Text = LabelTextRatio[Language];
lblDivText.Height = 14;
this.Controls.Add(lblDivText);
lblDiv = new Label();
lblDiv.Location = new Point(lblDivText.Left, lblDivText.Top + lblDivText.Height + 4);
lblDiv.Text = "";
this.Controls.Add(lblDiv);
lblQMinText = new Label();
lblQMinText.Location = new Point(lblDivText.Left + lblDivText.Width + 4, 4);
lblQMinText.Text = LabelTextQualityMin[Language];
lblQMinText.Height = 14;
this.Controls.Add(lblQMinText);
lblQMin = new Label();
lblQMin.Location = new Point(lblDivText.Left + lblDivText.Width + 4, lblQMinText.Top + lblQMinText.Height + 4);
lblQMin.Text = "";
this.Controls.Add(lblQMin);
lblQDeltaText = new Label();
lblQDeltaText.Location = new Point(lblQMinText.Left + lblQMinText.Width + 4, 4);
lblQDeltaText.Text = LabelTextClassInterval[Language];
lblQDeltaText.Height = 14;
this.Controls.Add(lblQDeltaText);
lblQDelta = new Label();
lblQDelta.Location = new Point(lblQMinText.Left + lblQMinText.Width + 4, lblQMinText.Top + lblQMinText.Height + 4);
lblQDelta.Text = "";
this.Controls.Add(lblQDelta);
lblSetOfRulesQText1 = new Label();
lblSetOfRulesQText1.Location = new Point(lblQDelta.Left + lblQDelta.Width, 4);
lblSetOfRulesQText1.Height = 14;
lblSetOfRulesQText1.Text = LabelTextRulesSetQuality1[Language];
this.Controls.Add(lblSetOfRulesQText1);
lblSetOfRulesQText2 = new Label();
lblSetOfRulesQText2.Location = new Point(lblSetOfRulesQText1.Left, lblSetOfRulesQText1.Top + lblSetOfRulesQText1.Height - 2);
lblSetOfRulesQText2.Height = 14;
lblSetOfRulesQText2.Text = LabelTextRulesSetQuality2[Language];
this.Controls.Add(lblSetOfRulesQText2);
lblSetOfRulesQ = new Label();
lblSetOfRulesQ.Location = new Point(lblSetOfRulesQText1.Left, lblSetOfRulesQText2.Top + lblSetOfRulesQText2.Height + 4);
lblSetOfRulesQ.Height = 14;
lblSetOfRulesQ.Text = "";
this.Controls.Add(lblSetOfRulesQ);
bLanguage = new Button();
bLanguage.Text = "EN / PL";
bLanguage.Location = new Point(lblSetOfRulesQText1.Left + lblSetOfRulesQText1.Width + 4, 4);
bLanguage.Size = new Size(bFillRandom.Width, bFillRandom.Height);
bLanguage.Click += new EventHandler(bLanguage_Click);
this.Controls.Add(bLanguage);
gridData = new DataGridView();
gridData.ColumnCount = VectorElementCount;
gridData.Location = new Point(4, bFillRandom.Top + bFillRandom.Height + 4);
gridData.AllowUserToAddRows = false;
int width;
int scrollBarWidth = 20;
width = 0;
for (int col = 0; col < VectorElementCount; col++)
{
gridData.Columns[col].HeaderText = GridDataHeader[Language, col];
gridData.Columns[col].Width = 57;
width += gridData.Columns[col].Width;
}
gridData.Width = width + scrollBarWidth + gridData.RowHeadersWidth;
gridData.SelectionMode = DataGridViewSelectionMode.FullRowSelect;
gridData.ColumnHeadersHeightSizeMode = DataGridViewColumnHeadersHeightSizeMode.DisableResizing;
gridData.ColumnHeadersHeight = 40;
gridData.Height = gridData.ColumnHeadersHeight + gridData.RowTemplate.Height * visibleDataRowCount;
this.Controls.Add(gridData);
gridRules = new DataGridView();
gridRules.ColumnCount = RuleElementCount;
gridRules.Location = new Point(4, gridData.Top + gridData.Height + 4);
gridRules.AllowUserToAddRows = false;
width = 0;
for (int col = 0; col < RuleElementCount; col++)
{
gridRules.Columns[col].HeaderText = GridRulesHeader[Language, col];
if (col == statXLessYIdx || col == statYLessZeroIdx)
gridRules.Columns[col].Width = 70;
else if (col == conclusionIdx)
gridRules.Columns[col].Width = 70;
else
gridRules.Columns[col].Width = 40;
width += gridRules.Columns[col].Width;
}
gridRules.Width = width + gridRules.RowHeadersWidth + 3;
gridRules.SelectionMode = DataGridViewSelectionMode.FullRowSelect;
gridRules.ColumnHeadersHeightSizeMode = DataGridViewColumnHeadersHeightSizeMode.DisableResizing;
gridRules.ColumnHeadersHeight = 40;
gridRules.Height = gridRules.ColumnHeadersHeight
+ gridData.RowTemplate.Height * visibleRulesRowCount;
gridRules.ScrollBars = ScrollBars.None;
this.Controls.Add(gridRules);
StartPosition = FormStartPosition.Manual;
Size = new Size(Screen.GetWorkingArea(this).Width, Screen.GetWorkingArea(this).Height);
Load += new EventHandler(Form1_Load);
bFillRandom.Click += new EventHandler(bFillRandom_Click);
b100PerCent.Click += new EventHandler(b100PerCent_Click);
b25PerCent.Click += new EventHandler(b25PerCent_Click);
}
}
}
/* Moduł 11_lang.cs */
/* Module 11_lang.cs */
using System;
using System.Windows.Forms;
namespace DataMiner
{
public partial class Form1 : Form
{
static int enUS = 0;
/*
static int plPL = 1;
*/
string[,] GridDataHeader =
{
{ "result X", "result Y", "attr A", "attr B", "attr C", "attr D", "attr E", "attr F", "attr G", "attr H" },
{ "wynik X", "wynik Y", "wartość A", "wartość B", "wartość C", "wartość D", "wartość E", "wartość F", "wartość G", "wartość H" }
};
string[,] GridRulesHeader =
{
{ "class X<Y", "quality % X<Y", "class Y<0", "quality % Y<0", "", "fact AB", "", "fact CD", "", "fact EF", "", "fact GH", "", "conclusion" },
{ "klasa X<Y", "jakość % X<Y", "klasa Y<0", "jakość % Y<0", "", "fakt AB", "", "fakt CD", "", "fakt EF", "", "fakt GH", "", "wniosek" }
};
string[] LabelTextRatio = { "Ratio", "Proporcja" };
string[] LabelTextClassInterval = { "Class interval", "Odstęp klas" };
string[] LabelTextQualityMin = { "Quality min", "Jakość min" };
string[] LabelTextRulesSetQuality1 = { "Rules set", "Jakość zbioru" };
string[] LabelTextRulesSetQuality2 = { "quality", "reguł" };
string[] CellValueIf = { "if", "jeżeli" };
string[] CellValueThen = { "then", "to" };
string[] CellValueAnd = { "and", "oraz" };
string[] CellValueOr = { "or", "lub" };
string[] BtnTextRandom = { "Random", "Losowo" };
int Language = enUS;
void bLanguage_Click(object sender, EventArgs e)
{
// Zamiana słów w oknie programu z angielskich na polskie i odwrotnie
// Zamiana będzie widoczna po kliknięciu jednego z przycisków do generowania zbiorów danych
// Bidirectional replacing words in program window English-Polish, Polish-English
// Replacement will be displayed after you click one of buttons to generate data sets
Language = (Language + 1) % 2;
bFillRandom.Text = BtnTextRandom[Language];
lblDivText.Text = LabelTextRatio[Language];
lblQMinText.Text = LabelTextQualityMin[Language];
lblQDeltaText.Text = LabelTextClassInterval[Language];
for (int col = 0; col < VectorElementCount; col++)
gridData.Columns[col].HeaderText = GridDataHeader[Language, col];
for (int col = 0; col < RuleElementCount; col++)
gridRules.Columns[col].HeaderText = GridRulesHeader[Language, col];
lblSetOfRulesQText1.Text = LabelTextRulesSetQuality1[Language];
lblSetOfRulesQText2.Text = LabelTextRulesSetQuality2[Language];
}
}
}