Sieci neuronowe, aproksymacja i rozpoznawanie pisma
Deti
W gotowcu tym znajdziecie praktyczne zastosowanie sieci neuronowych wraz z implementacją. Być może pomoże to wam rozwiązać problemy, których nie mało na forum - zwłaszcza z algorytmem wstecznej propagacji błędów. Zapraszam do lektury.
Co zawiera gotowiec?
W skrócie jest to opis mojej implementacji sieci neuronowej - projekt nazywa się HSynapse (aktualna wersja to 0.5), pisałem go przez kilka miesięcy. Zawiera on zestaw narzędzi do posługiwania się sieciami neuronowymi, między innymi zautomatyzowane budowanie sieci neuronowych, serializacja, uczenie się wraz ze szczegółowych wglądem w sam proces uczenia się. Nie jest to zatem "jedna" specyficzna sieć, lecz cała biblioteka, do posługiwania się dowolną siecią neuronową. Oprócz tego gotowiec zawiera część tzw. praktyczną - program do aproksymacji funkcji oraz rozpoznawania cyfr z dużą dokładnością.
Czego artykuł nie zawiera?
Nie znajdziesz tu żadnej teorii, dokładnych opisów elementów sieci, algorytmów, wzorów matematycznych - to wszystko znajduje się w implementacji. Odsyłam do Google.
Przegląd biblioteki
Całość możliwa do ściągnięcia Tu: hsynapse.rar [#]_
Solucja Zawiera:
- HSynapse - główna biblioteka z całą niezbędną logiką
- HSynapseTests - testy jednostkowe. Jeśli nie posiadasz programu NUnit [#]_, możesz śmiało usunąć tą część
- HSynapseTools - rozszerzenie o dodatkowe narzędzia. O tym później
- Approximator - przykładowa aplikacja - aproksymator funkcji
- OCR - przykładowa aplikacja - rozpoznawanie cyfr
- SignalInspectorSample - przykład użycia klasy SignalInspector. O tym później.
.. [#] Paczka nie zawiera gotowych wartości wag dla programu OCR, które ważą ponad 20MB. Te do ściągnięcia tu: http://www.filesonic.com/file/891263194/synapsedata.rar
.. [#] NUnit jest darmowym narzędziem do testowania oprogramowania (wykonuje testy jednostkowe). Szczegóły na http://www.nunit.org/
Wszystko jest napisane w C#/.NET 4.0.
Biblioteka HSynapse
Jest to "mózg" całego projektu. Tu się znajdują wszystkie potrzebne klasy do stworzenia sieci neuronowej. Poniżej, krótki przegląd najważniejszych klas.
MultilayerPerceptron
Klasa reprezentująca sieć wielowarstwową z możliwością wstecznej propagacji błędów.
MLPGenerator
Klasa, która ma za zadanie zbudowanie sieci, czyli instancji MultilayerPerceptron na podstawie podanych parametrów takich jak liczba warstw, neuronów w każdej warstwie itd.
MLPSerializer
Służy do (de)serializacji sieci. Innymi słowy - zapisuje stan wag w celu późniejszego wczytania.
NetworkStructure
Zawiera informacje o strukturze sieci, czyli warstwy, elementy itd.
SignalInspector
Pozwala śledzić cały proces przesyłania sygnałów w sieci oraz w razie potrzeby zapisywać do logu. Przydatne szczególnie do nauki lub debuggowania sieci, jeśli coś idzie niezgodnie z założeniami.
Unit, Link, Bias, Neuron
Są to klasy reprezentujące poszczególne elementy sieci. Połączenia między nimi realizowane są dzięki klasie Connection. Klasy te są związane z klasą NetworkStructure. Ta ostatnia posiada referencję do wszystkich elementów sieci.
Poniżej rysunek z diagramem hierarchii elementów sieci:
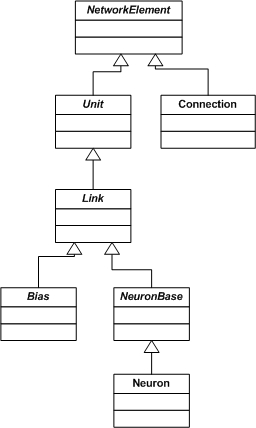
Połączenia pomiędzy elementami są realizowane dzięki klasie Connection. Aby zapewnić odpowiednią szybkość procesu uczenia się, poszczególne elementy mają referencję do instancji klasy Connection, z którymi się łącza, a dodatkowo - sama klasa Connection posiada referencję do tych obiektów. Tak zatem każdy element posiada referencję do innych elementów, z którymi jest połączony (referencje cykliczne). Wszystko to buduje generator.

Oprócz powyższych, biblioteka zawiera oczywiście o wiele więcej klas, jednak póki co objaśnienie ich nie jest potrzebne.
Biblioteka HSynapseTools
Głównym domownikiem tego projektu jest klasa MLPWatchdog. Dziedziczy ona bezpośrednio z klasy MultilayerPerceptron. Jest to klasa, która praktycznie zapewnia powodzenie w nauce - sprawia nadzów nad procesem uczenia się. Klasa obserwuje proces uczenia się (wsteczna propagacja błędów), i w razie porażki, zmienia losowo wagi sieci i zaczyna cały proces od nowa. Liczba takich cykli jest modyfikowalna. Jest to bardzo wygodne narzędzie, ponieważ zwalnia programistę od martwienia czy sieć się nauczy. W praktyce, stosując BP (back-propagation) sieć nie zawsze zdoła się nauczyć. Jednak stosując klasę MLPWatchdog i ustawiając np. 10 prób, mamy praktycznie pewność sukcesu - porażka w 10-ciu próbach jest mało prawdopodobna, zakładając oczywiście, że nasza sieć jest odpowiednia do zadania, jakie chcemy na niej przeprowadzić.
Aproksymacja
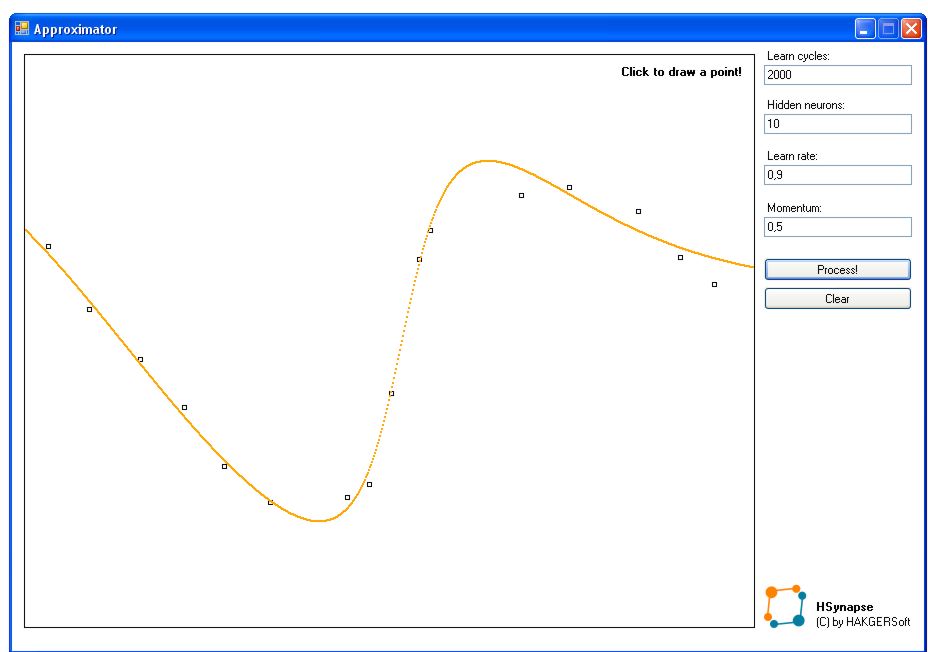
Dość nudnych opisów - czas coś stworzyć. Aplikacja Approximator jest najprostszym przykładem użycia sieci - aproksymuje ona funkcje na podstawie podanych wartości w punktach.
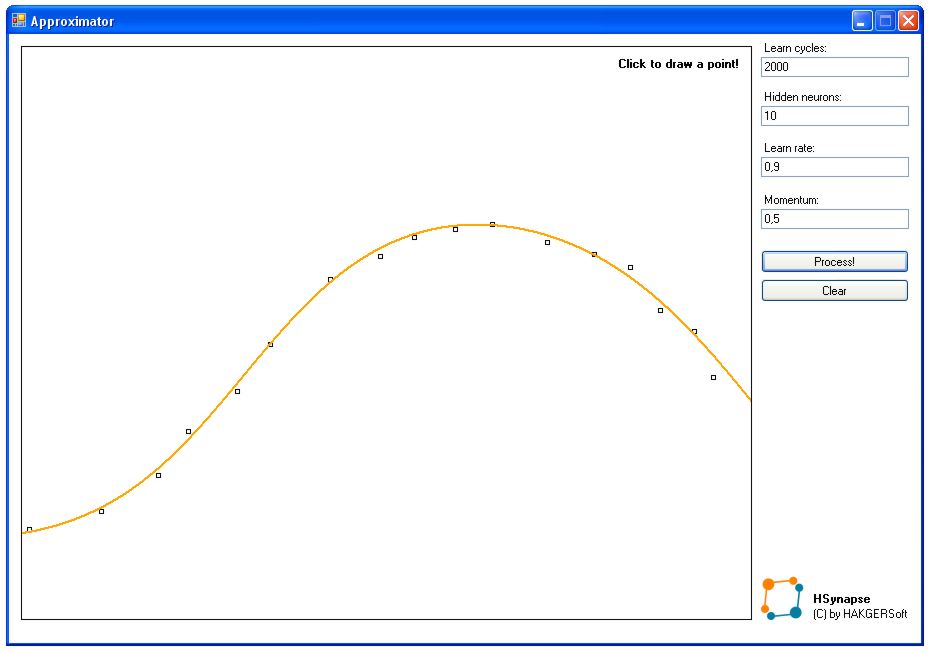
Aproksymacja została osiągnięta przez użycie 3-warstwowej sieci. Zarówno warstwa wejściowa jak i wyjściowa zawiera 1 neuron, natomiast liczba neuronów w warstwie ukrytej jest modyfikowalna (domyślnie 10). Mamy zatem 12 neuronów w sieci (tylko tyle wystarczy aby uzyskać porządną aproksymację!).
Kod do zbudowania sieci:
int hiddenNeurons=int.Parse(textBox2.Text);
int[] layers = new int[] { 1,hiddenNeurons,1 };
MultilayerPerceptron ann=new MLPGenerator().Create(layers,1,new Sigmoid(2));
Jak widać generator oprócz informacji o warstwach, przyjmuje więcej parametrów. "Jedynka" oznacza, że użyjemy w sieci Biasu o wartości 1. Natomiast Sigmoid jest typem funkcji aktywacji neuronu.
Wagi sieci są losowane z przedziału (-1,1). Współczynnik uczenia wynosi 0,9. Liczba epok domyślnie 2000.
Jak to w zasadzie działa ? Otóż program zbiera informacje o punktach, gdzie x jest wartością na wejściu sieci, natomiast y - spodziewaną wartością na wyjściu. Następnie program przepuszcza wszystkie wartości przez sieć i tak modyfikuje wagi, aby wartości na wyjściu zgadzały się ze spodziewanymi (algorytm wstecznej propagacji błędów, w skrócie BP). Dla 10 punktów, mamy 10*2000= 20 tysięcy poprawek wag każdego elementu sieci. Na szczęście to wszystko trwa milisekundy.
Po nauczeniu sieci, program przepuszcza wszystkie wartości x przez sieć i uzyskuje odpowiedź dla każdego argumentu funkcji.
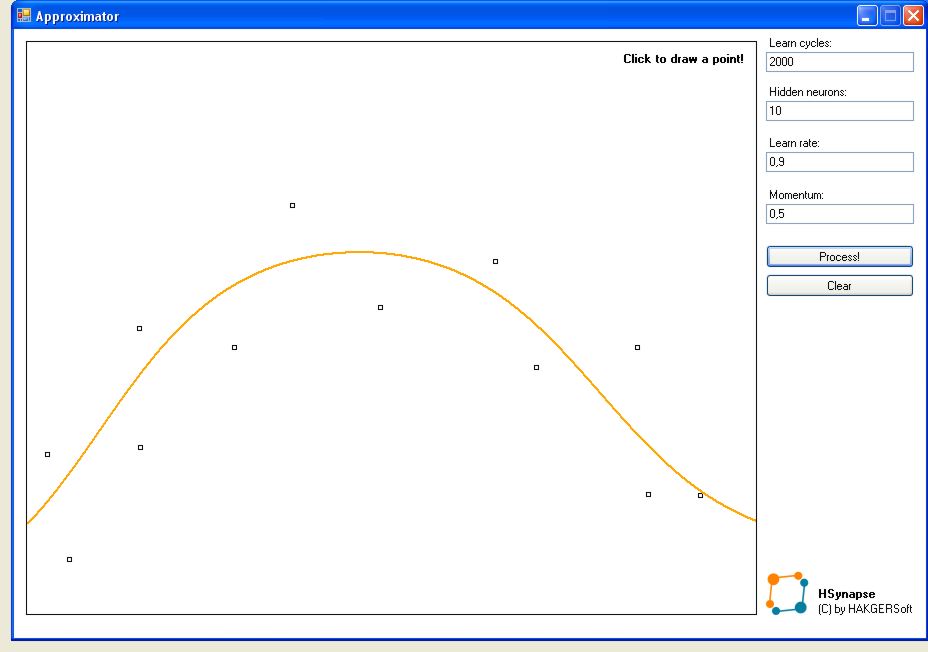
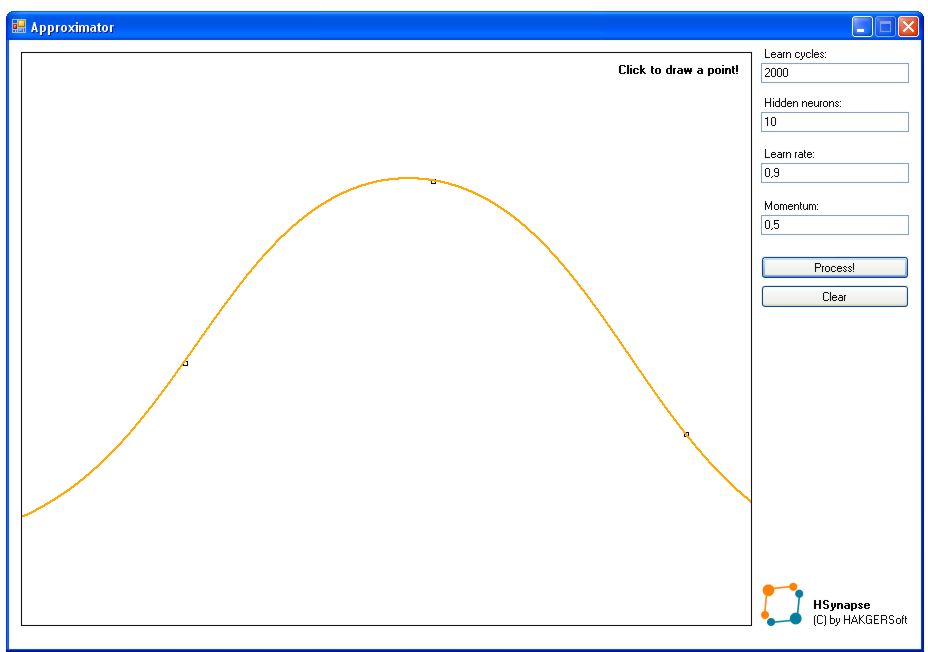
Rozpoznawanie pisma
Zadanie to jest o wiele bardziej trudne niż zwykła aproksymacja. Program rozpoznając pismo musi "jakoś" wiedzieć, że dany znak jest podobny do znaku pożądanego. Tylko nie wiadomo co to znaczy "podobny". Dla ludzi jest to intuicyjne, jednak nie dla maszyny. Okazuje się, że niewielkie zmiany wielkości, przesunięcia, rotacja powodują że zwykła sieć neuronowa nie radzi sobie z tym problemem. Zwykła w tym przypadku znaczy sieć wielowarstową z pełnymi połączeniami [#]_, jakiej to użyto do aproksymacji.
.. [#] każdy neuron warstwy n był połączony z każdym neuronem warstwy (n+1).
Rozwiązanie problemu, który tu znajdziecie pochodzi ze strony http://yann.lecun.com. Jest to strona, która zawiera wiele materiałów dot. uczenia maszyn. Została tam zaprezentowana między innymi sieć, która służy właśnie do klasyfikacji obrazów 2D. W skrócie: CNN (Convolution neural network). Przyznam się szczerze, że nie wiem jaka jest polska nazwa takiej sieci, więc nazywajmy ją po prostu "splot".
Czym się różni zwykła sieć (MultilayerPerceptron) od splotu?
-
MultilayerPerceptron do większości zastosowań jest złożony z trzech warstw: warstwy wejściowej, ukrytej oraz wyjściowej. To starczy aby rozwiązać proste problemy (zobacz: separacja liniowa http://en.wikipedia.org/wiki/Multilayer_perceptron ). Splot może się składać z wielu warstw. W programie do rozpoznawania pisma użyto 5 warstw neuronów.
-
Warstwy MultilayerPerceptron są zawsze w pełni połączone. Warstwy w splocie nie muszą być w pełni połączone (w pewnych warstwach mogą). Ich połączenia są ściśle budowane.
-
Splot posiada współdzielenie wag. MultilayerPerceptron posiada tyle wag ile połączeń między neuronami.
Przegląd sieci
Poglądowy schemat sieci wygląda tak:
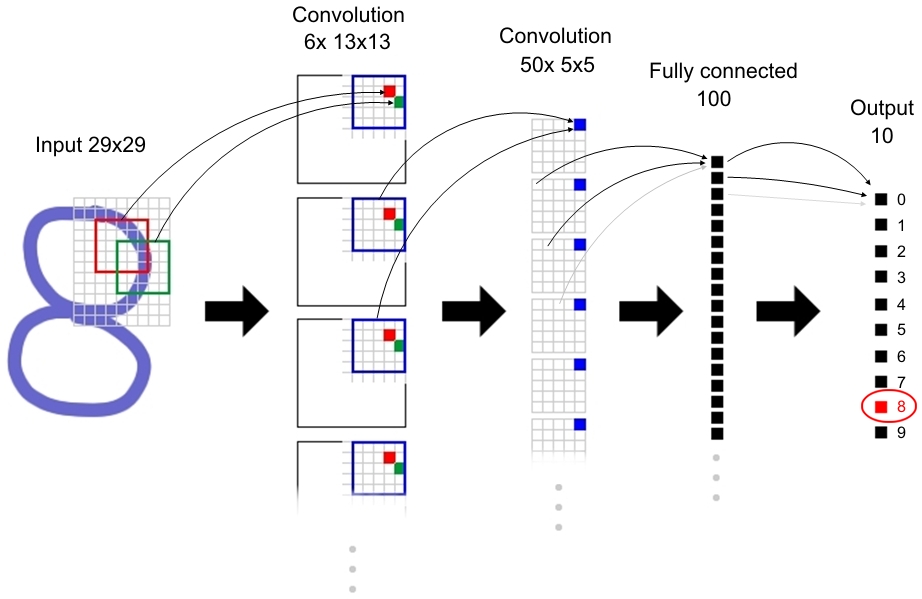
Nie będę tu kłamał - jest to dość skomplikowane.
Warstwa wejściowa jest praktycznie digitalizacją znaku na wejściu (na przykładzie, pisana cyfra "8"). Obrazy zostały znormalizowane do rozmiaru 29x29, a zatem 841 pikseli, tyle samo neuronów. Neurony te mogą przyjmować jedną z dwóch wartości: 1 (czarny) lub -1 (biały) [#]_. W ten sposób sygnały neuronów opisują stan koloru odpowiadającym im pikseli.
.. [#] W programie użyto wartości +/- 0.8, aby nie dopuścić do "nasycenia".
Warstwa druga jest o wiele bardziej złożona. Można zauwarzyć, że sama dzieli się na kolejne "warstwy". Aby nie komplikować sprawy - nazwijmy te nowe warstwy - mapami. A zatem druga warstwa składa się z 6-ciu map, a każda mapa zawiera 13x13=169 neuronów. W sumie warstwa posiada 6x169=1014 neuronów. Aby zrozumieć strukturę splotu - musimy wrócić do warstwy pierwszej. Kolorem czerwonym oraz zielonym zaznaczyłem dwa kwadraty, które pokrywają pewne obszary. Obszary te pokrywają powierzchnię 5x5 pikseli, a zatem zawierają 25 neuronów. Taką paczkę 25-ciu neuronów pokrywającą dany obszar nazwijmy kernel'em.
Neurony warstwy drugiej łączą się tylko! z konkretnymi neuronami warstwy poprzedniej, a dokładniej mówiąc - z odpowiednim kernelem (zgodnie z obrazkiem). To znaczy, neurony warstwy drugiej mają po 26 połączeń do warstwy pierwszej (25 do kernela oraz 1 dla biasu). Mimo, że na obrazku strzałki są narysowane tylko do pierwszej mapy, kernele są połączone ze wszystkimi mapami. Zadaniem map i kerneli jest wyodrębnienie charakterystycznego dla każdego znaku wyglądu. Dodatkowo powierzchnie kerneli nachodzą na siebie w celu lepszej klasyfikacji. Dlatego też liczba połączeń każdego neuronu warstwy pierwszej jest różna i zależy od umiejscowienia (przynależności do poszczególnych kerneli).
Warstwa trzecia jest kolejną warstwą z pomieszanymi połączeniami. Składa się z 50-ciu map, każda jest mapą 5x5. Zatem warstwa ta posiada 1250 neuronów. Połączenie jest podobne - tym razem jednak jest jednak więcej kerneli z warstwy poprzedniej - z uwagi na liczbę map (kernele są wyprowadzone z każdej z 6-ciu map).
Czwarta warstwa składa się ze 100 neuronów. Każdy ze 100 neuronów łączy się z każdym neuronem warstwy poprzedniej. Jest to zatem zwykłe połączenie jak w przypadku warstw klasy MultilayerPerceptron.
I wreszcie, ostatnia warstwa - warstwa wyjściowa. Składa się z 10-ciu neuronów, każdy reprezentuje cyfrę (0-9). Ponieważ nasz program ma za zadanie rozpoznawać cyfry - ostatnia warstwa ma "wykazać" o jaką cyfrę chodziło. W przypadku cyfry "8" - tylko neuron oznaczony jako "8" ma odpowiadać sygnałem +0.8, natomiast pozostałe 8 neuronów - sygnałem -0.8.
A zatem nasza sieć ma 3215 neuronów (oraz bias).
Nauka
Proces nauki jest długi i żmudny. Celem jest nauczenie sieci jak najlepszego rozpoznawania znaków. Ograniczymy się tylko do cyfr 0-9. W tym celu użyłem próbki znalezionej w Internecie, które zawierają wszystkie cyfry (pisane przez różne osoby). Fragment takiej próbki - poniżej.

Próbki te są dostępne (zobacz link na górze artykułu) wraz z z plikiem xml, który zawiera nauczone wartości wag do dobrego rozpoznawania znaków.
Wymiary obrazków nie są identyczne, ale rozmiary cyfr są takie same. Jest to około 5000 wariantów każdej cyfry, co daje razem 50 tysięcy wzorów. Każda z próbek została przepuszczona przez sieć 10 razy (10 epok wstecznej propagacji błędów) a zatem sieci zadano pół miliona próbek. Proces 10-ciu epok trwał około 12 godzin. Mój Athlon przeżywał wtedy ciężkie chwile :)
Aplikacja "OCR" posiada dwa ważne przyciski - "Load" oraz "Save". Po otwarciu aplikacji, sieć jest nienauczona - nie potrafi rozpoznawać cyfr. Można poświęcić kilka godzin i ją nauczyć - lub - użyć przycisku "Load", który wczyta nauczoną sieć z pliku ocr.xml.
Uwaga! - przycisk "Save" powoduje zapisanie aktualnej sieci do pliku ocr.xml, a zatem nadpisanie tego pliku.
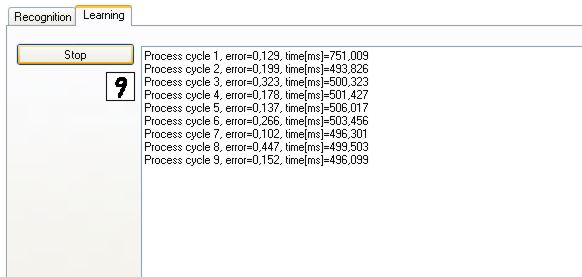
Współczynnik uczenia sieci wynosi 0.0005. Wydaje się to mało, ale jest to odpowiednia wartość dla tak dużej liczby wzorców. Gdyby współczynnik uczenia był większy, sieć wykazywała by za duże odchylenia podczas kolejnych wzorców (jedne wzorce powodowałyby wypaczenia wcześniej nauczonych). Dzięki małemu współczynnikowi uczenia sieć, powoli ale sukcesywnie, uczy się wszystkich wzorców - nie powodując przy tym szkód, jeśli któryś ze wzorców jest mocno odkształcony.
Wzorce są podawane w paczkach po 10 cyfr. To znaczy: pierw pierwsza cyfra z każdego obrazka, następnie druga, trzecia itd. Dodatkowo, kolejność podawania cyfr jest losowana (podobno zwiększa to jakość nauki sieci).
Kiedy już błąd średniokwadratowy sygnałów na wyjściu osiąga niskie wartości (~0.1), można sprawdzić sieć.
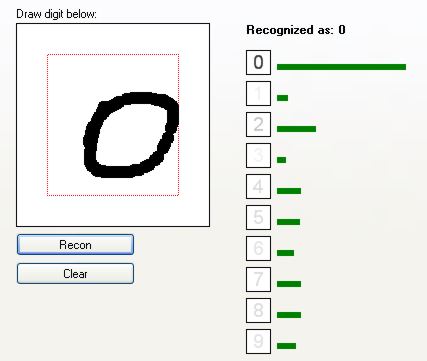
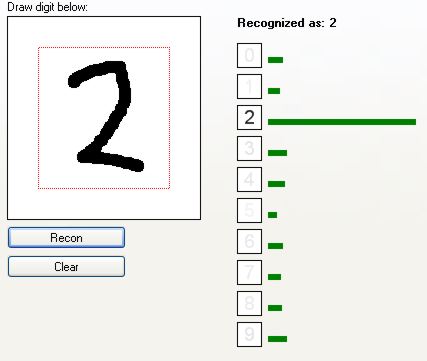
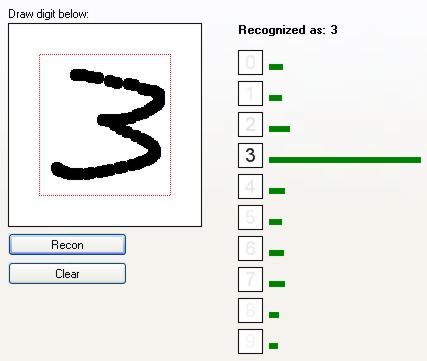
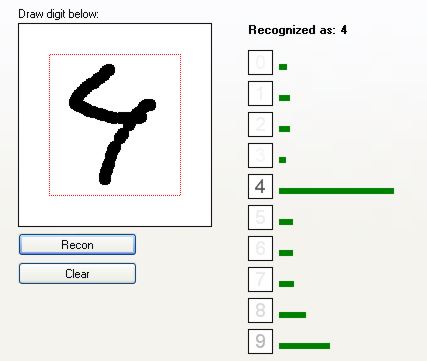
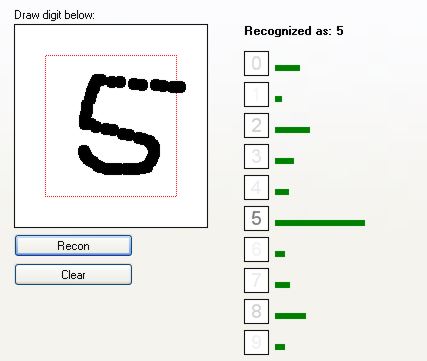
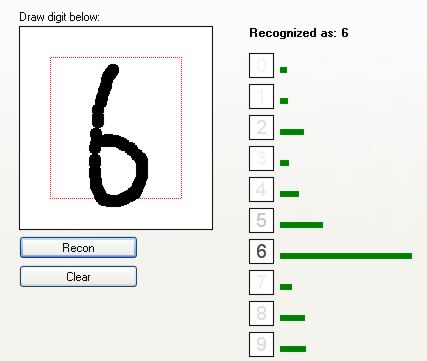
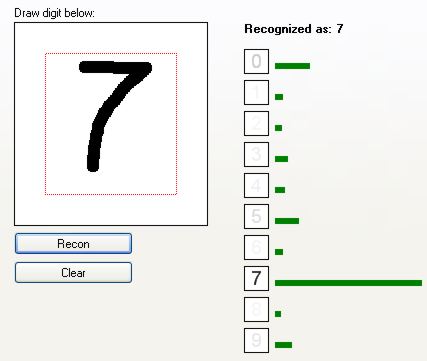
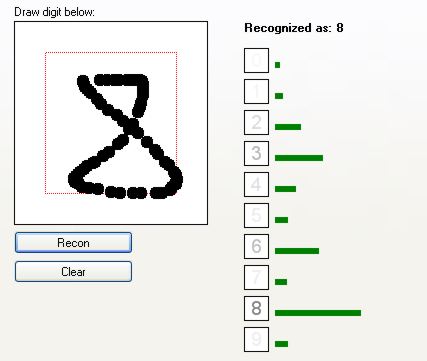
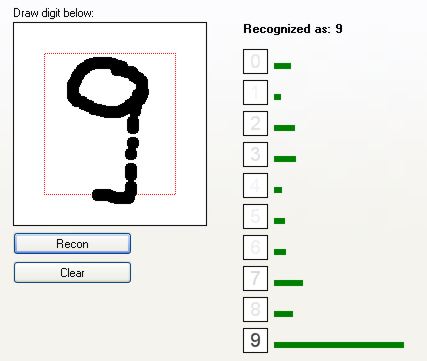
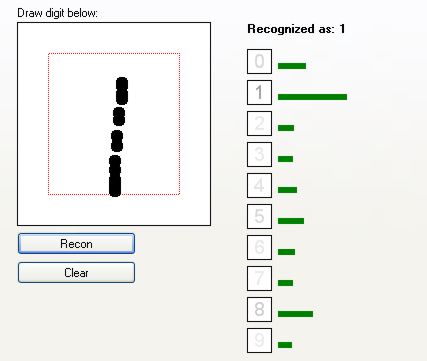
Jak widać, sieć całkiem dobrze rozpoznaje cyfry. Zobaczmy, jak radzi sobie z cięższymi przypadkami:

Sieć rozpoznała to jako "2". Jednak widać, że drugim kandydatem jest cyfra "7". Małe niezdecydowanie.
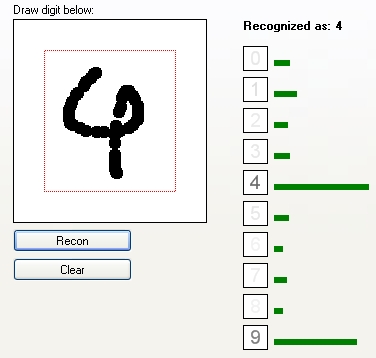
Rozpoznano jako "4". Choć i "9" było blisko.
Mimo, że większość cyfr jest dobrze rozpoznawana, zdarza się, że sieć błędnie rozpozna cyfrę. Poniżej kilka sposobów, które mogą jeszcze bardziej ulepszyć proces nauki:
- Zwiększenie liczby epok (sieć nauczy się bardziej "dogłębnie" podanych próbek)
- Zmiana współczynnika uczenia się (wraz z kolejnymi epokami należy sukcesywnie zmniejszać wartość współczynnika uczenia się)
- Zniekształcenia - nauka byłaby bardziej wartościowa, gdyby każdą próbkę cyfry - dodatkowo zniekształcać (obroty, przesunięcia, zmiana rozmiaru) i traktować jako osobne próbki.
Użycie powyższych pomysłów z pewnością wydłużyłoby proces nauki, jednak rozpoznanie byłoby o wiele lepsze. Podobną technikę można zastosować do nauki liter.
SignalInspector
Na koniec - opis klasy, która może pomóc w debuggowaniu aplikacji lub też nauce algorytmu wstecznej propagacji błędów. Klasa nazywa się SignalInspector i można ją przypisać do sieci (właściwość Inspector). Można teraz ustawić poziom logowania i widzieć cały proces uczenia się w okienku "Output" w Visual Studio - neuron po neuronie.
Oczywiście takie logowanie zwalnia aplikacje dlatego należy go używać tylko w razie konieczności (szczególnie nie zalecałbym do debuggowania nauki rozpoznawania znaków :).
Autorzy:
- HAKGERSoft (biblioteka, rozpoznawanie pisma)
- Sebastian Kijaczko (biblioteka, aproksymator)
Jak mówi stara prawda - kto szuka ten znajdzie.
https://github.com/ZimaXXX/neuron
Fajny artykuł oraz bibliotek. Kapitalna robota. Dziękuję.
Ja też bym się bardzo ucieszył z ponownego z działającego linka. Więc dołączam się do prośby o ponowny upload bądź usunięcie artykuły jeżeli biblioteki nie są już dostępne.
Dołączam się do poprzedników i jeśli to możliwe prosił bym o reupa, z góry dziękuję
Również proszę o ponowny upload